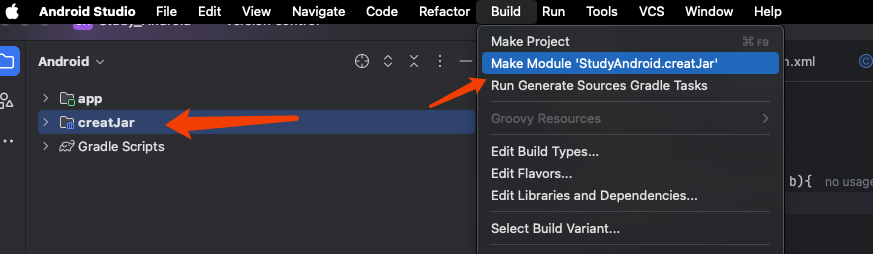
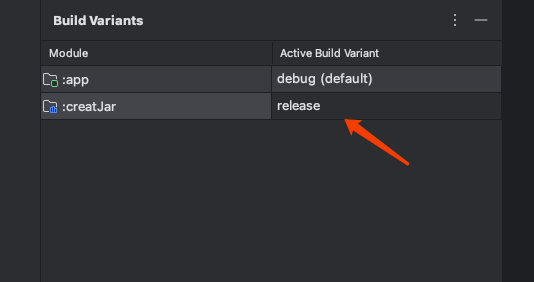
生成Android能动态加载的Jar包 这样可以直接build生成jar包,生成的jar包会在如下图片的路径下
具体项目里没显示也不知道为什么。如果想要更改成release版本只需在structure里
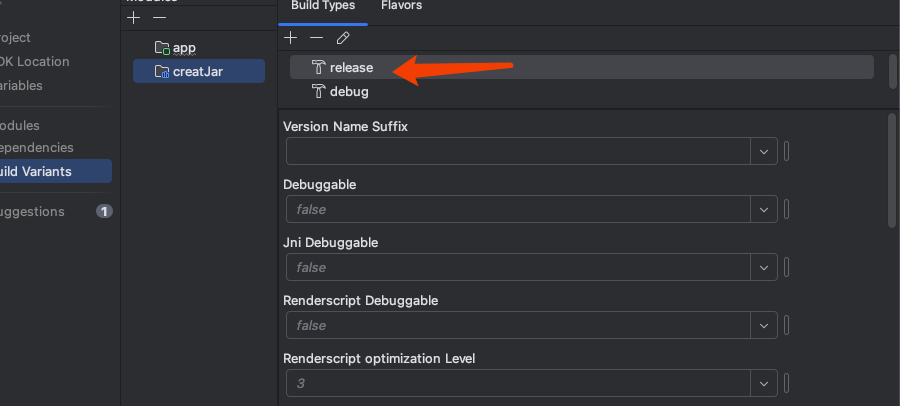
之后选择
将其改变为release即可
利用gradle打jar包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 task makeJar (type: Copy ) { delete 'build/libs/myjar.jar' from ('build/intermediates/aar_main_jar/release/' ) into ('build/libs/' ) include ('classes.jar' ) rename ('classes.jar' , 'myjar.jar' ) } makeJar.dependsOn (build)
然后在命令行输入
或者直接点击运行也行
之后可以利用d8 将生成的jar包提取到桌面
1 d8 --dex --output=test.jar /Users/ocean/Cybersecurity/Android_Project/Study_Android/creatJar/build/intermediates/aar_main_jar/release/syncReleaseLibJars/classs.jar
动态加载Jar包 参考:https://blog.csdn.net/fengyulinde/article/details/79623743 https://blog.csdn.net/u012121105/article/details/129297666
这里主要记录下重要的逻辑
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 package com.lgf.dynamicload.demo;import android.os.Bundle;import android.os.Environment;import android.support.v7.app.AppCompatActivity;import android.view.View;import android.widget.Toast;import com.lgf.plugin.IDynamic;import java.io.File;import dalvik.system.DexClassLoader;public class MainActivity extends AppCompatActivity { @Override protected void onCreate (Bundle savedInstanceState) { super .onCreate(savedInstanceState); setContentView(R.layout.activity_main); } public void showMessage (View view) { File dexPathFile = new File (Environment.getExternalStorageDirectory() + File.separator + "plugin.jar" ); String dexPath = dexPathFile.getAbsolutePath(); String dexDecompressPath = getDir("dex" , MODE_PRIVATE).getAbsolutePath(); DexClassLoader dexClassLoader = new DexClassLoader (dexPath, dexDecompressPath, null , getClassLoader()); Class libClazz = null ; try { libClazz = dexClassLoader.loadClass("com.lgf.base.DynamicTest" ); IDynamic lib = (IDynamic) libClazz.newInstance(); Toast.makeText(this , lib.show(), Toast.LENGTH_SHORT).show(); } catch (Exception e) { e.printStackTrace(); } } }
记得添加下权限
1 <uses-permission android:name ="android.permission.READ_EXTERNAL_STORAGE" />
NDK编程 JNI 是什么 1 2 3 JNI 是 Java Native Interface 的缩写,即 Java 的本地接口。 目的是使得 Java 与本地其他语言(如 C/C++)进行交互。 JNI 是属于 Java 的,与 Android 无直接关系。
NDK 是什么 1 2 3 NDK 是 Native Development Kit 的缩写,是 Android 的工具开发包。 作用是快速开发 C/C++ 的动态库,并自动将动态库与应用一起打包到 apk。 NDK 是属于 Android 的,与 Java 无直接关系。
JNI 与 NDK 的关系 1 JNI 是实现的目的,NDK 是 Android 中实现 JNI 的手段。
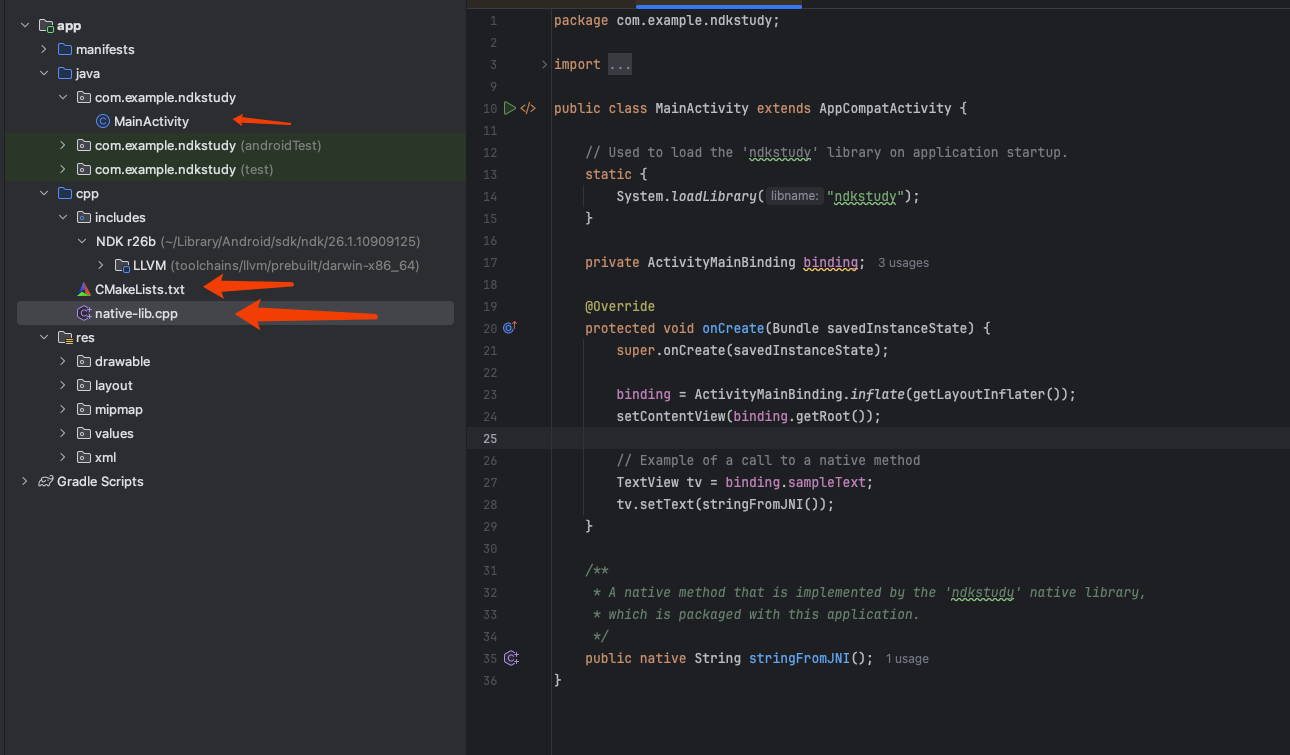
第一个JNI程序 新建一个c++Native程序,Android Studio 会自动帮你生成一个可执行的 Hello World 程序,我们简单看一下这个工程
其中 cpp 目录就是我们的 C/C++ 代码、预编译库的默认路径了,而 CMakeList.txt 就是编译的脚本文件了
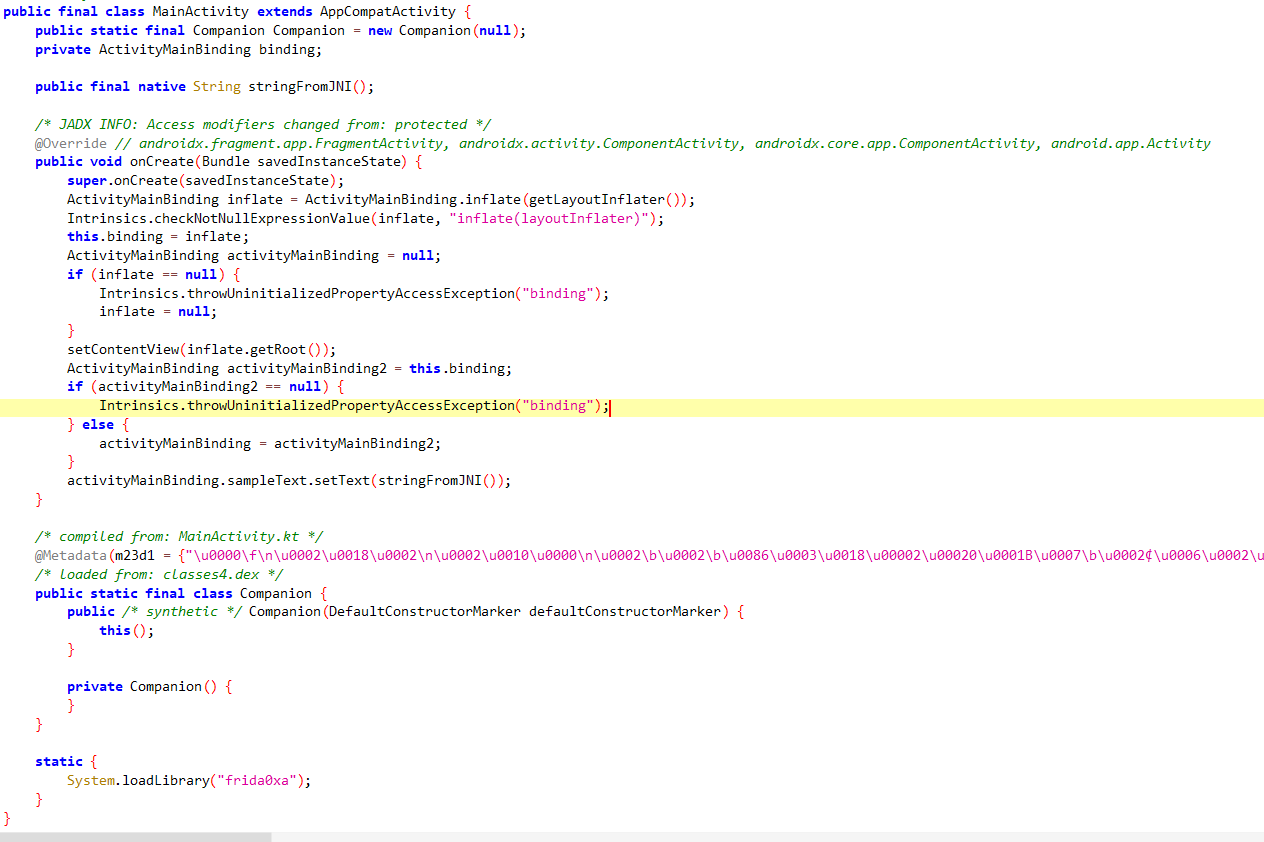
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 package com.example.ndkstudy; import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle; import android.widget.TextView; import com.example.ndkstudy.databinding.ActivityMainBinding; public class MainActivity extends AppCompatActivity { static { System.loadLibrary("ndkstudy" ); } private ActivityMainBinding binding; @Override protected void onCreate (Bundle savedInstanceState) { super .onCreate(savedInstanceState); binding = ActivityMainBinding.inflate(getLayoutInflater()); setContentView(binding.getRoot()); TextView tv = binding.sampleText; tv.setText(stringFromJNI()); } public native String stringFromJNI () ; }
Java 调用本地方法,是使用 native 关键字。而本例中,本地方法的实现是在一个叫做 “native-lib” 的动态库里(动态库的名称是在 CMakeList.txt 中指定的),要想使用这个动态库,就必须先加载这个库,即 System.loadLibrary(native-lib) 。这些都是 Java 的语法定义。
看一下cpp的代码
1 2 3 4 5 6 7 8 9 10 #include <jni.h> #include <string> extern "C" JNIEXPORT jstring JNICALL Java_com_example_ndkstudy_MainActivity_stringFromJNI ( JNIEnv* env, jobject ) { std ::string hello = "Hello from C++" ; return env->NewStringUTF(hello.c_str()); }
上面提到的 public native String stringFromJNI() 方法的实现就是在这里,那怎么知道 Java 中的某个 native 方法是对应的 cpp 中的哪个方法呢?这就和 JNI 的注册有关了,本例中使用的是静态注册,即 “Java包名类名_方法名” 的形式,其中包名也是用下划线替代点号。
总结下流程:
1 2 3 4 1.Gradle 调用您的外部构建脚本 CMakeLists.txt。 2.CMake 按照构建脚本中的命令将 C++ 源文件 native-lib.cpp 编译到共享的对象库中,并命名为 libnative-lib.so,Gradle 随后会将其打包到 APK 中。 3.运行时,应用的 MainActivity 会使用 System.loadLibrary() 加载原生库。现在,应用可以使用库的原生函数 stringFromJNI()。 4.MainActivity.onCreate() 调用 stringFromJNI(),这将返回“Hello from C++”并使用这些文字更新 TextView。
在列一下CMakeLists.txt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 cmake_minimum_required(VERSION 3.22 .1 ) # Declares the project name. The project name can be accessed via ${ PROJECT_NAME}, # Since this is the top level CMakeLists.txt, the project name is also accessible # with ${CMAKE_PROJECT_NAME} (both CMake variables are in-sync within the top level # build script scope). project("ndkstudy" ) # Creates and names a library, sets it as either STATIC # or SHARED, and provides the relative paths to its source code. # You can define multiple libraries, and CMake builds them for you. # Gradle automatically packages shared libraries with your APK. # # In this top level CMakeLists.txt, ${CMAKE_PROJECT_NAME} is used to define # the target library name; in the sub-module's CMakeLists.txt, ${PROJECT_NAME} # is preferred for the same purpose. # # In order to load a library into your app from Java/Kotlin, you must call # System.loadLibrary() and pass the name of the library defined here; # for GameActivity/NativeActivity derived applications, the same library name must be # used in the AndroidManifest.xml file. add_library(${CMAKE_PROJECT_NAME} SHARED # List C/C++ source files with relative paths to this CMakeLists.txt. native-lib.cpp) # Specifies libraries CMake should link to your target library. You # can link libraries from various origins, such as libraries defined in this # build script, prebuilt third-party libraries, or Android system libraries. target_link_libraries(${CMAKE_PROJECT_NAME} # List libraries link to the target library android log)
解释下含义用gpt
cmake_minimum_required(VERSION 3.22.1)`
含义 :声明本项目使用的最低 CMake 版本是 3.22.1。这是为了确保 CMake 的语法和功能版本兼容。
project("ndkstudy")
含义 :定义项目名称为 ndkstudy。
作用 :
会设置变量 PROJECT_NAME 为 ndkstudy;
在顶层 CMakeLists.txt 中,PROJECT_NAME 与 CMAKE_PROJECT_NAME 是一样的;
这个名称也通常被用作生成库文件的前缀,例如生成 libndkstudy.so。
add_library(${CMAKE_PROJECT_NAME} SHARED native-lib.cpp)
含义 :
结果 :
会构建出一个名为 libndkstudy.so 的共享库。
target_link_libraries(${CMAKE_PROJECT_NAME} android log)
含义 :
效果 :
可以在 native-lib.cpp 中使用 Android 系统的功能,例如打印 log 信息。
数据类型 基本数据类型
Java 数据类型
JNI 本地类型
C/C++ 数据类型
数据类型描述
booleanjbooleanunsigned charC/C++ 无符号 8 位整数
bytejbytesigned charC/C++ 有符号 8 位整数
charjcharunsigned shortC/C++ 无符号 16 位整数
shortjshortsigned shortC/C++ 有符号 16 位整数
intjintsigned intC/C++ 有符号 32 位整数
longjlongsigned longC/C++ 有符号 64 位整数
floatjfloatfloatC/C++ 32 位浮点数
doublejdoubledoubleC/C++ 64 位浮点数
上表显示了java对应的c的数据类型使用JNI进行中转
引用数据类型 以下是你Java 类类型 与 JNI 引用类型 的对应关系
Java 类类型
JNI 引用类型
类型描述
java.lang.Objectjobject表示任何 Java 对象,或没有特定 JNI 类型的对象(实例方法参数)
java.lang.StringjstringJava 的 String 字符串对象
java.lang.ClassjclassJava 的 Class 类型对象(用于静态方法的强制参数)
Object[]jobjectArrayJava 中任意对象数组的表示形式
boolean[]jbooleanArrayJava 基本类型 boolean 的数组表示形式
byte[]jbyteArrayJava 基本类型 byte 的数组表示形式
char[]jcharArrayJava 基本类型 char 的数组表示形式
short[]jshortArrayJava 基本类型 short 的数组表示形式
int[]jintArrayJava 基本类型 int 的数组表示形式
long[]jlongArrayJava 基本类型 long 的数组表示形式
float[]jfloatArrayJava 基本类型 float 的数组表示形式
double[]jdoubleArrayJava 基本类型 double 的数组表示形式
java.lang.ThrowablejthrowableJava 的异常类型,包括所有子类
voidvoid无返回值(用于 JNI 方法返回类型)
数据类型描述符
Java 类型
JNI 类型描述符
说明
intI整型
longJ长整型
byteB字节型
shortS短整型
charC字符型(UTF-16)
floatF单精度浮点型
doubleD双精度浮点型
booleanZ布尔型
voidV无返回值
Java 引用类型描述符
Java 类型
JNI 类型描述符
示例
引用类型(类)
L<类的全限定名>;Ljava/lang/String; 表示 String
数组类型(任意维度)
[ + 元素类型描述符[I 表示 int[],[Ljava/lang/String; 表示 String[]
JNI 方法签名格式
示例 Java 方法签名
对应 JNI 方法描述符
void foo()()V
int sum(int a, int b)(II)I
String concat(String a, String b)(Ljava/lang/String;Ljava/lang/String;)Ljava/lang/String;
int[] getData()()[I
void setValues(float[] values, boolean flag)([FZ)V
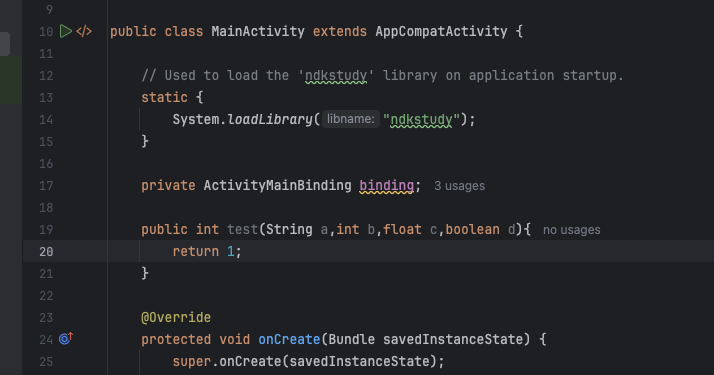
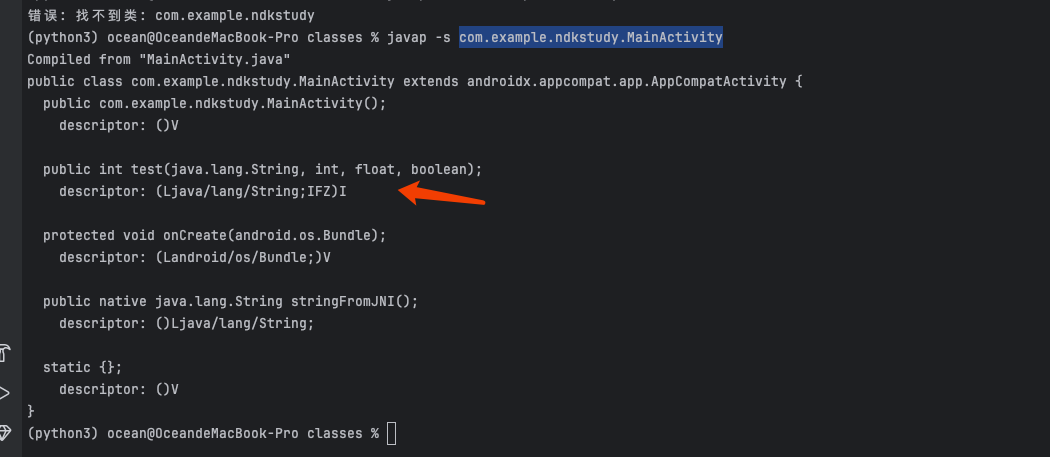
可以验证一下
可以看到我们定义的一个方法,编译一下之后用jabap看一下他的签名
1 javap -s com.example.ndkstudy.MainActivity
符合表格的规则。来写一个读取scard目录的文件功能练习
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 public class MainActivity extends AppCompatActivity {private final static int MY_PERMISSIONS_REQUEST_WRITE_CODE = 11 ; static {System.loadLibrary("ndk01" ); } public int testFun (String a, double b, long c) {return 1 ;} private ActivityMainBinding binding; @Override protected void onCreate (Bundle savedInstanceState) {super .onCreate(savedInstanceState); binding = ActivityMainBinding.inflate(getLayoutInflater()); setContentView(binding.getRoot()); testFun("aa" , 4.5 , 5 ); TextView tv = binding.sampleText;tv.setText(stringFromJNI()); tv.setOnClickListener(new View .OnClickListener() { @Override public void onClick (View v) {int ret = ContextCompat.checkSelfPermission(MainActivity.this , Manifest.permission.WRITE_EXTERNAL_STORAGE);if (ret == PackageManager.PERMISSION_GRANTED){Log.i("tttttttt" , "已经有写SDCard的权限了" ); String fp1 = Environment.getExternalStoragePublicDirectory(Environment.DIRECTORY_DOWNLOADS).getAbsolutePath();String fc = readSDCardFile(fp1+"/b.txt" );Log.i("tttttttt" , "文件内容:" + fc); }else { Log.i("tttttttt" , "还没有写SDCard的权限" ); ActivityCompat.requestPermissions(MainActivity.this , new String []{Manifest.permission.WRITE_EXTERNAL_STORAGE}, MY_PERMISSIONS_REQUEST_WRITE_CODE); } } }); } @Override public void onRequestPermissionsResult (int requestCode, @NonNull String[] permissions, @NonNull int [] grantResults) {super .onRequestPermissionsResult(requestCode, permissions, grantResults); switch (requestCode){case MY_PERMISSIONS_REQUEST_WRITE_CODE:{if (grantResults.length > 0 && grantResults[0 ] != -1 ){Log.i("tttttttt" , "写SDCard权限申请成功" ); }else { Log.i("tttttttt" , "写SDCard权限申请失败" ); } break ;} case 33 :{ Log.i("tttttttt" , "这里是其他权限申请的结果" ); break ;} } } public native String stringFromJNI () ; public native String readSDCardFile (String filePath) ;}
cpp实现读取文件的功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 #include <jni.h> #include <string> #include <android/log.h> #define LOGI(...) __android_log_print(ANDROID_LOG_INFO, "tttttttt" , __VA_ARGS__) #define LOGD(...) __android_log_print(ANDROID_LOG_DEBUG, "tttttttt" , __VA_ARGS__) #define LOGW(...) __android_log_print(ANDROID_LOG_WARN, "tttttttt" , __VA_ARGS__) #define LOGE(...) __android_log_print(ANDROID_LOG_ERROR, "tttttttt" , __VA_ARGS__) extern "C" JNIEXPORT jstring JNICALLJava_a_b_c_ndk01_MainActivity_stringFromJNI ( JNIEnv* env, jobject ) {std ::string hello = "Hello from C++" ;return env->NewStringUTF(hello.c_str());} extern "C" JNIEXPORT jstring JNICALL Java_a_b_c_ndk01_MainActivity_readSDCardFile (JNIEnv *env, jobject thiz, jstring file_path) { const char * filePath = env->GetStringUTFChars(file_path, nullptr); FILE *fp = fopen(filePath, "r" ); if (fp == nullptr) { LOGE("Failed to open file: %s" , filePath); env->ReleaseStringUTFChars(file_path, filePath); return env->NewStringUTF("open file failed" ); } char buffer[1024 ]; std ::string result; while (fgets(buffer, sizeof (buffer), fp) != nullptr) { result += buffer; } fclose(fp); env->ReleaseStringUTFChars(file_path, filePath); return env->NewStringUTF(result.c_str()); }
JNI方法 参考: https://blog.csdn.net/afei__/article/details/81016413
写一个例子,反射获取类和方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 extern "C" JNIEXPORT jint JNICALL Java_a_b_c_ndk01_MainActivity_callJavaFunFromJNI (JNIEnv *env, jobject thiz, jobject param) { jclass jclass_student = env->GetObjectClass(param); jclass jclass_student2 = env->FindClass("a/b/c/ndk01/Student" ); jmethodID jmethodId_study = env->GetMethodID(jclass_student, "study" , "(I)Ljava/lang/String;" ); int flag = 34 ; jobject jobject_ret = env->CallObjectMethod(param, jmethodId_study, flag); char * t = (char *)env->GetStringUTFChars((jstring)jobject_ret, 0 ); LOGI("ndk call study ret: %s" , t); return flag; } extern "C" JNIEXPORT jstring JNICALL Java_a_b_c_ndk01_MainActivity_callStaticJavaFunFromJNI (JNIEnv *env, jobject thiz) { jclass jclass_student2 = env->FindClass("a/b/c/ndk01/Student" ); jmethodID jmethodId_calcLength = env->GetStaticMethodID(jclass_student2, "calcLength" , "(Ljava/lang/String;)I" ); jstring jstring_param = env->NewStringUTF("hahahaha" ); jint jint_ret = env->CallStaticIntMethod(jclass_student2, jmethodId_calcLength, jstring_param); LOGI("ndk call calcLength ret: %d" , jint_ret); return jstring_param; }
JNI注册 静态注册 静态注册就是通过 JNIEXPORT 和 JNICALL 两个宏定义声明,在虚拟机加载 so 时发现上面两个宏定义的函数时就会链接到对应的 native 方法。
注册的规则:
Java + 包名 + 类名 + 方法名
其中使用下划线将每部分隔开,包名也使用下划线隔开,如果名称中本来就包含下划线,将使用下划线加数字替换。
示例 包名:com.afei.jnidemo ,类名:MainActivity )
1 2 3 4 5 6 7 8 9 10 11 public native String stringFromJNI () ;JNIEXPORT jstring JNICALL Java_com_afei_jnidemo_MainActivity_stringFromJNI ( JNIEnv *env, jobject instance) ; public native String stringFrom_JNI () ;JNIEXPORT jstring JNICALL Java_com_afei_jnidemo_MainActivity_stringFrom_1JNI (JNIEnv *env, jobject instance) ;
动态注册 通过 RegisterNatives 方法手动完成 native 方法和 so 中的方法的绑定,这样虚拟机就可以通过这个函数映射表直接找到相应的方法了。
来看一个例子
1 2 public native String stringFromJNI () ; public static native int add (int a, int b) ;
一般在JNI_OnLoad完成注册
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 #include <jni.h> #include <string> #include "log.hpp" extern "C" { jstring stringFromJNI (JNIEnv *env, jobject instance) { std ::string hello = "Hello from C++" ; return env->NewStringUTF(hello.c_str()); } jint add (JNIEnv *env, jclass clazz, jint a, jint b) { return a + b; } jint RegisterNatives (JNIEnv *env) { jclass clazz = env->FindClass("com/afei/jnidemo/MainActivity" ); if (clazz == NULL ) { LOGE("con't find class: com/afei/jnidemo/MainActivity" ); return JNI_ERR; } JNINativeMethod methods_MainActivity[] = { {"stringFromJNI" , "()Ljava/lang/String;" , (void *) stringFromJNI}, {"add" , "(II)I" , (void *) add} }; return env->RegisterNatives(clazz, methods_MainActivity, sizeof (methods_MainActivity) / sizeof (methods_MainActivity[0 ])); } jint JNI_OnLoad (JavaVM *vm, void *reserved) { JNIEnv *env = NULL ; if (vm->GetEnv((void **) &env, JNI_VERSION_1_6) != JNI_OK) { return JNI_ERR; } jint result = RegisterNatives(env); LOGD("RegisterNatives result: %d" , result); return JNI_VERSION_1_6; } }
RegisterNatives方法解析 1 2 3 4 5 定义: jint RegisterNatives(jclass clazz, const JNINativeMethod* methods, jint nMethods) clazz:指定的类,即 native 方法所属的类 methods:方法数组,这里需要了解一下 JNINativeMethod 结构体 nMethods:方法数组的长度
JNINativeMethod
1 2 3 4 5 typedef struct { const char * name; const char * signature; void * fnPtr; } JNINativeMethod;
Android.mk 和 CMake 语法 参考:Android.mk 语法和变量介绍 CMakeLists.txt 语法介绍与实例演练
Android Studio 中使用 NDK gradle 配置 cmake,及各参数详解
gardle 配置 ndk 指定 ABI: abiFilters 详解
APK文件结构 参考: https://bbs.kanxue.com/thread-278112.htm
assets文件夹 assets 这里存放的是静态资源文件(图片,视频等),这个文件夹下的资源文件不会被编译。不被编译的资源文件是指在编译过程中不会被转换成二进制代码的文件,而是直接被打包到最终的程序中。这些文件通常是一些静态资源,如图片、音频、文本文件等。
lib文件夹 lib:.so库(c或c++编译的动态链接库)。APK文件中的动态链接库(Dynamic Link Library,简称DLL)是一种可重用的代码库,它包含在应用程序中,以便在运行时被调用。这些库通常包含许多常见的函数和程序,可以在多个应用程序中共享,从而提高了代码的复用性和效率。
lib文件夹下的每个目录都适用于不同的环境下,armeabi-v7a目录基本通用所有android设备,arm64-v8a目录只适用于64位的android设备,x86目录常见用于android模拟器,x86-64目录适用于支持x86_64架构的Android设备(适用于支持通常称为“x86-64”的指令集的 CPU)
META-INF:在Android应用的APK文件中,META-INF文件夹是存放数字签名相关文件的文件夹,包含以下三个文件:
MANIFEST.MF:MANIFEST.MF 是一个摘要清单文件,它包含了 APK 文件中除自身外所有文件的数字摘要。这些摘要通常是通过特定的哈希算法(如 SHA - 1、SHA - 256 等)对文件内容进行计算得到的,用于确保文件内容在传输或存储过程中未被篡改。
CERT.SF:CERT.SF 文件存储了 MANIFEST.MF 文件的数字摘要以及 MANIFEST.MF 中每个文件条目的数字摘要的二次摘要。开发者使用自己的私钥对 CERT.SF 进行签名,以保证 CERT.SF 文件内容的完整性和真实性。
CERT.RSA:CERT.RSA 文件包含了使用开发者私钥对 CERT.SF 文件进行签名得到的数字签名以及签名时所使用的数字证书。当验证 APK 的签名时,系统会使用数字证书中的公钥来验证 CERT.SF 文件的数字签名是否有效,从而确保 CERT.SF 文件未被篡改,进而验证 MANIFEST.MF 文件和整个 APK 的完整性。
AndroidManifest.xml配置文件 AndroidManifest.xml是Android应用程序中最重要的文件之一,它包含了应用程序的基本信息,如应用程序的名称、图标、版本号、权限、组件(Activity、Service、BroadcastReceiver、Content Provider)等等。在应用程序运行时,系统会根据这个文件来管理应用程序的生命周期,启动和关闭应用程序,管理应用程序的组件等等。
我们来了解一下AndroidManifest.xml文件的主要组成部分:
manifest标签
manifest标签是AndroidManifest.xml文件的根标签,它包含了应用程序的基本信息,如包名、版本号、SDK版本、应用程序的名称和图标等等。
application标签
application标签是应用程序的主要标签,它包含了应用程序的所有组件,如Activity(活动)、Service(服务)、Broadcast Receiver(广播接收器)、Content Provider(内容提供者)等等。在application标签中,也可以设置应用程序的全局属性,如主题、权限等等。
activity标签
activity标签定义了一个Activity组件,它包含了Activity的基本信息,如Activity的名称、图标、主题、启动模式等等。在activity标签中,还可以定义Activity的布局、Intent过滤器等等。
service标签
service标签定义了一个Service组件,它包含了Service的基本信息,如Service的名称、图标、启动模式等等。在service标签中,还可以定义Service的Intent过滤器等等。
receiver标签
receiver标签定义了一个BroadcastReceiver组件,它包含了BroadcastReceiver的基本信息,如BroadcastReceiver的名称、图标、权限等等。在receiver标签中,还可以定义BroadcastReceiver的Intent过滤器等等。
provider标签
provider标签定义了一个Content Provider组件,它包含了Content Provider的基本信息,如Content Provider的名称、图标、权限等等。在provider标签中,还可以定义Content Provider的URI和Mime Type等等。
uses-permission标签
uses-permission标签定义了应用程序需要的权限,如访问网络、读取SD卡等等。在应用程序安装时,系统会提示用户授权这些权限。
uses-feature标签
uses-feature标签定义了应用程序需要的硬件或软件特性,如摄像头、GPS等等。在应用程序安装时,系统会检查设备是否支持这些特性。
以上是AndroidManifest.xml文件的主要组成部分,它们共同定义了应用程序的基本信息和组件,是应用程序的重要配置文件。现在如果看起来有点懵,没关系,后面实战会使用到它的,以后也会对它进行详解,那时你或许会有一点对它的理解了。
resources.arsc文件 resources.arsc文件是Android应用程序的资源文件之一,它是一个二进制文件,包含了应用程序的所有资源信息,例如布局文件、字符串、图片等。这个文件在应用程序编译过程中由aapt工具生成,并被打包进APK文件中。
resources.arsc文件的主要作用是提供资源的索引和映射关系。它将资源文件名、类型、值等信息映射到一个唯一的整数ID上。这个ID在R文件中定义,并且可以通过代码中的R类来引用。例如,R.layout.main表示布局文件main.xml对应的ID,R.string.app_name表示字符串资源app_name对应的ID。
当应用程序运行时,系统会根据R类中的ID来查找对应的资源,并将其加载到内存中,供应用程序使用。这个过程是通过解析resources.arsc文件和R类实现的。通过这种方式,应用程序可以方便地访问和使用资源,而不需要手动处理资源文件的位置和命名等问题。
需要注意的是,resources.arsc文件只包含资源的索引和映射关系,并不包含实际的资源内容。实际的资源内容存储在res文件夹中,按照资源类型和名称进行组织。当应用程序需要使用资源时,系统会根据resources.arsc文件中的索引信息找到对应的资源文件,并将其加载到内存中。
总之,resources.arsc文件是Android应用程序的资源文件之一,包含了资源的索引和映射关系。它和R类一起构成了应用程序访问和使用资源的基础。通过解析resources.arsc文件和使用R类,应用程序可以方便地加载和使用资源。
参考其他的文章Android资源管理及资源的编译和打包过程分析 - 掘金 (juejin.cn)
(32条消息) 手把手教你解析Resources.arsc_beyond702的博客-CSDN博客
Android逆向:resource.arsc文件解析(Config List) - 掘金 (juejin.cn)
(32条消息) resource.arsc二进制内容解析 之 Dynamic package reference_BennuCTech的博客-CSDN博客
res文件夹 res:资源文件目录,二进制格式。实际上,APK文件下的res文件夹并不是二进制格式,而是经过编译后的二进制资源文件。在Android应用程序开发中,资源文件通常是以XML格式存储的,如布局文件、字符串资源、颜色资源等。在编译时,Android编译器会将这些XML资源文件编译成二进制格式的资源文件,以提高应用程序的运行效率和安全性。虽然res文件夹下的二进制资源文件不能直接编辑和修改,但是开发者仍然可以通过Android提供的资源管理工具,如aapt、apktool等,来反编译和编辑这些资源文件的。
在res文件夹中,主要包含以下子文件夹和文件:
res子目录
存储的资源类型
animator/用于定义属性动画 的 XML 文件。
anim/用于定义补间动画 的 XML 文件。属性动画也可保存在此目录中,但为了区分这两种类型,属性动画首选 animator/ 目录。
color/定义颜色状态列表的 XML 文件。如需了解详情,请参阅颜色状态列表资源 。
drawable/位图文件(PNG、.9.png、JPG 或 GIF)或编译为以下可绘制资源子类型的 XML 文件:位图文件九宫图(可调整大小的位图)状态列表形状动画可绘制对象其他可绘制对象如需了解详情,请参阅可绘制资源 。
mipmap/适用于不同启动器图标密度的可绘制对象文件。如需详细了解如何使用 mipmap/ 文件夹管理启动器图标,请参阅将应用图标放在 mipmap 目录中 。
layout/用于定义界面布局的 XML 文件。如需了解详情,请参阅布局资源 。
menu/用于定义应用菜单(例如选项菜单、上下文菜单或子菜单)的 XML 文件。如需了解详情,请参阅菜单资源 。
raw/需以原始形式保存的任意文件。如要使用原始 InputStream 打开这些资源,请使用资源 ID(即 R.raw.*filename*)调用 Resources.openRawResource()。但是,如需访问原始文件名和文件层次结构,请考虑将资源保存在 assets/ 目录(而非 res/raw/)下。assets/ 中的文件没有资源 ID,因此您只能使用 AssetManager 读取这些文件。
values/包含字符串、整数和颜色等简单值的 XML 文件。其他 res/ 子目录中的 XML 资源文件会根据 XML 文件名定义单个资源,而 values/ 目录中的文件可描述多个资源。对于此目录中的文件,<resources> 元素的每个子元素均会定义一个资源。例如,<string> 元素会创建 R.string 资源,<color> 元素会创建 R.color 资源。由于每个资源均使用自己的 XML 元素进行定义,因此您可以随意命名文件,并在某个文件中放入不同的资源类型。但是,您可能需要将独特的资源类型放在不同的文件中,使其一目了然。例如,对于可在此目录中创建的资源,下面给出了相应的文件名约定:arrays.xml 用于资源数组(类型化数组 )colors.xml 用于颜色值 dimens.xml 用于维度值 strings.xml 用于字符串值 styles.xml 用于样式 如需了解详情,请参阅字符串资源 、样式资源 和更多资源类型 。
xml/可在运行时通过调用 Resources.getXML() 读取的任意 XML 文件。各种 XML 配置文件(例如搜索配置 )都必须保存在此处。
font/带有扩展名的字体文件(例如 TTF、OTF 或 TTC),或包含 <font-family> 元素的 XML 文件。如需详细了解以资源形式使用的字体,请参阅将字体添加为 XML 资源 。
dex文件结构 https://cloud.tencent.com/developer/article/1663852 https://juejin.cn/post/6844903847647772686
如何将编译dex文件
1 ./d8 --debug --output dex输出路径 class文件
再来一个简洁的图
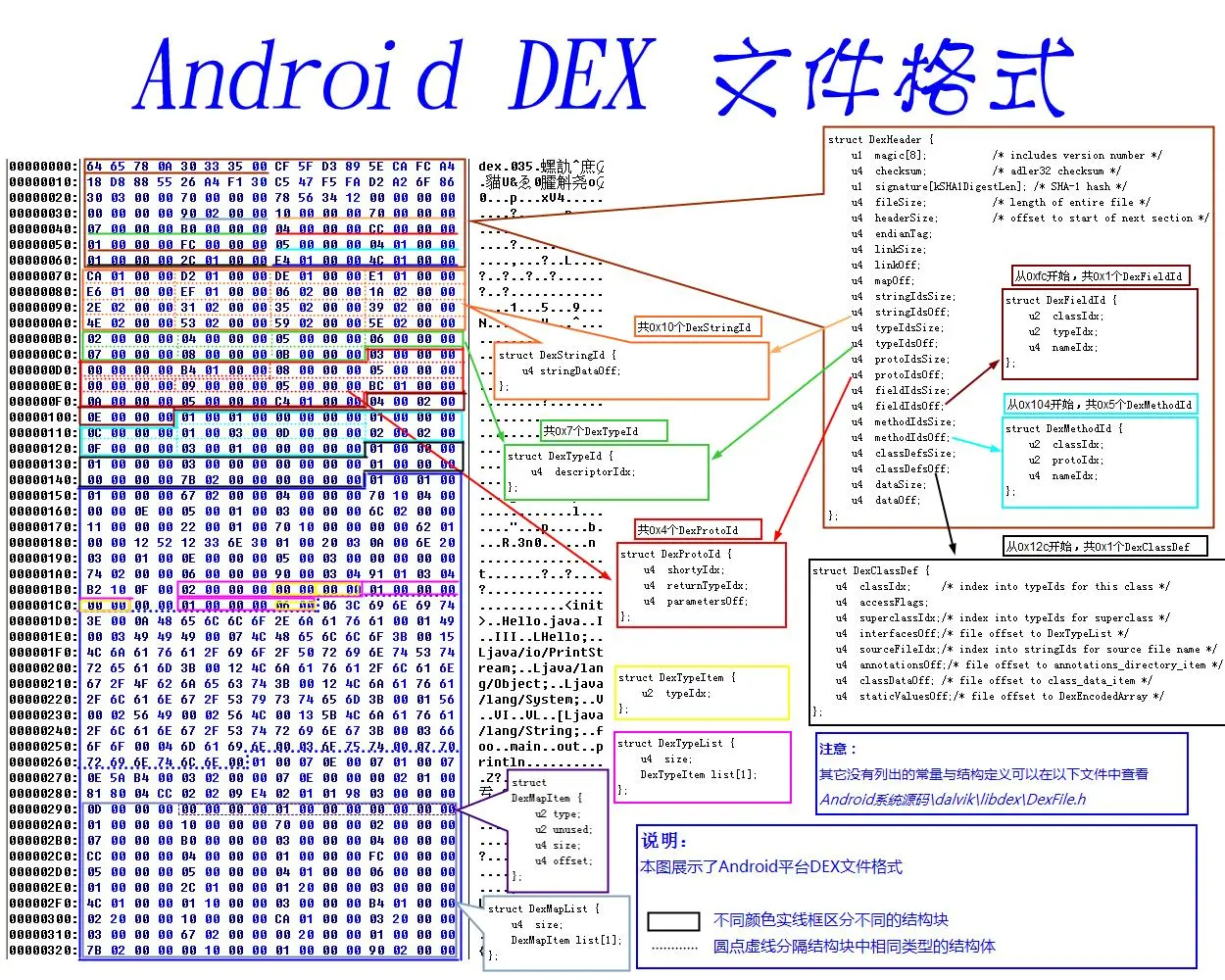
header : DEX 文件头,记录了一些当前文件的信息以及其他数据结构在文件中的偏移量string_ids : 字符串的偏移量type_ids : 类型信息的偏移量proto_ids : 方法声明的偏移量field_ids : 字段信息的偏移量method_ids : 方法信息(所在类,方法声明以及方法名)的偏移量class_def : 类信息的偏移量data : : 数据区link_data : 静态链接数据区
从 header 到 data 之间都是偏移量数组,并不存储真实数据,所有数据都存在 data 数据区,根据其偏移量区查找。对 DEX 文件有了一个大概的认识之后,我们就来详细分析一下各个部分。
DEX 文件头部分的具体格式可以参考 DexFile.h 中的定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 struct DexHeader { u1 magic[8 ]; u4 checksum; u1 signature[kSHA1DigestLen]; u4 fileSize; u4 headerSize; u4 endianTag; u4 linkSize; u4 linkOff; u4 mapOff; u4 stringIdsSize; u4 stringIdsOff; u4 typeIdsSize; u4 typeIdsOff; u4 protoIdsSize; u4 protoIdsOff; u4 fieldIdsSize; u4 fieldIdsOff; u4 methodIdsSize; u4 methodIdsOff; u4 classDefsSize; u4 classDefsOff; u4 dataSize; u4 dataOff; };
magic 一般是常量,用来标记 DEX 文件,它可以分解为:
1 文件标识 dex + 换行符 + DEX 版本 + 0
字符串格式为 dex\n035\0,十六进制为 0x6465780A30333500。
checksum 是对去除 magic 、 checksum 以外的文件部分作 alder32 算法得到的校验值,用于判断 DEX 文件是否被篡改。
signature 是对除去 magic 、 checksum 、 signature 以外的文件部分作 sha1 得到的文件哈希值。
endianTag 用于标记 DEX 文件是大端表示还是小端表示。由于 DEX 文件是运行在 Android 系统中的,所以一般都是小端表示,这个值也是恒定值 0x12345678。
string_ids string_ids 是一个表,保存了 所有字符串的引用地址
1 2 3 struct DexStringId { u4 stringDataOff; };
先来写一个工具类后面的也都用这个工具类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public int readInt (byte [] data, int offset) { return ((data[offset] & 0xFF )) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int cur; int shift = 0 ; do { cur = data[offset + count] & 0xFF ; result |= (cur & 0x7F ) << shift; shift += 7 ; count++; } while ((cur & 0x80 ) != 0 ); return new int []{result, count}; } public String readString (byte [] data, int offset) { int end = offset; while (data[end] != 0 ) end++; return new String (data, offset, end - offset, StandardCharsets.UTF_8); }
解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public void parseStringIds (byte [] dexData) { int stringIdsSize = readInt(dexData, 0x38 ); int stringIdsOff = readInt(dexData, 0x3C ); System.out.println("Total strings: " + stringIdsSize); for (int i = 0 ; i < stringIdsSize; i++) { int stringDataOff = readInt(dexData, stringIdsOff + i * 4 ); int [] result = readUleb128(dexData, stringDataOff); int utf16Size = result[0 ]; int stringOffset = stringDataOff + result[1 ]; String value = readString(dexData, stringOffset); System.out.printf("string[%d] = %s\n" , i, value); } }
type_ids 1 2 3 struct DexTypeId { u4 descriptorIdx; };
type_ids 表示的是类型信息,descriptorIdx 指向 string_ids 中元素。根据索引直接在上一步读取到的字符串池即可解析对应的类型信息,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 int typeIdsSize = Utils.readInt(dexData, 0x40 );int typeIdsOff = Utils.readInt(dexData, 0x44 );for (int i = 0 ; i < typeIdsSize; i++) { int stringIndex = Utils.readInt(dexData, typeIdsOff + i * 4 ); int stringIdsOff = Utils.readInt(dexData, 0x3C ); int stringDataOff = Utils.readInt(dexData, stringIdsOff + stringIndex * 4 ); int [] result = Utils.readUleb128(dexData, stringDataOff); int size = result[0 ]; int offset = stringDataOff + result[1 ]; String typeString = Utils.readString(dexData, offset); System.out.println("type[" + i + "] = " + typeString); }
proto_ids 1 2 3 4 5 struct DexProtoId { u4 shortyIdx; u4 returnTypeIdx; u4 parametersOff; };
proto_ids 表示方法声明信息,它包含以下三个变量:
shortyIdx : 指向 string_ids ,表示方法声明的字符串
returnTypeIdx : 指向 type_ids ,表示方法的返回类型
parametersOff : 方法参数列表的偏移量DexTypeList 来表示:
1 2 3 4 5 6 7 8 struct DexTypeList { u4 size; DexTypeItem list [1 ]; }; struct DexTypeItem { u2 typeIdx; };
size 表示方法参数的个数,参数用 DexTypeItem 表示,它只有一个属性 typeIdx,指向 type_ids 中对应项。
解析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 import java.io.FileInputStream;import java.io.IOException;import java.nio.charset.StandardCharsets;public class DexProtoParser { public static void main (String[] args) throws IOException { FileInputStream fis = new FileInputStream ("your.dex" ); byte [] dexData = fis.readAllBytes(); fis.close(); parseProtoIds(dexData); } public static void parseProtoIds (byte [] dexData) { int protoIdsSize = readInt(dexData, 0x44 ); int protoIdsOff = readInt(dexData, 0x48 ); System.out.println("Total proto_ids: " + protoIdsSize); for (int i = 0 ; i < protoIdsSize; i++) { int base = protoIdsOff + i * 12 ; int shortyIdx = readInt(dexData, base); int returnTypeIdx = readInt(dexData, base + 4 ); int parametersOff = readInt(dexData, base + 8 ); String shorty = getStringById(dexData, shortyIdx); String returnType = getTypeString(dexData, returnTypeIdx); String[] params = getParamTypeList(dexData, parametersOff); System.out.printf("proto[%d]: shorty=%s, return=%s, params=%s\n" , i, shorty, returnType, String.join(", " , params)); } } public static int readInt (byte [] data, int offset) { return ((data[offset] & 0xFF )) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public static int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int shift = 0 ; int b; do { b = data[offset + count] & 0xFF ; result |= (b & 0x7F ) << shift; shift += 7 ; count++; } while ((b & 0x80 ) != 0 ); return new int []{result, count}; } public static String getStringById (byte [] data, int stringId) { int stringIdsOff = readInt(data, 0x3C ); int stringDataOff = readInt(data, stringIdsOff + stringId * 4 ); int [] result = readUleb128(data, stringDataOff); int contentOffset = stringDataOff + result[1 ]; return readString(data, contentOffset); } public static String getTypeString (byte [] data, int typeIdx) { int typeIdsOff = readInt(data, 0x40 ); int descriptorIdx = readInt(data, typeIdsOff + typeIdx * 4 ); return getStringById(data, descriptorIdx); } public static String[] getParamTypeList(byte [] data, int parametersOff) { if (parametersOff == 0 ) return new String [0 ]; int size = readInt(data, parametersOff); String[] types = new String [size]; for (int i = 0 ; i < size; i++) { int typeIdx = ((data[parametersOff + 4 + i * 2 ] & 0xFF ) | ((data[parametersOff + 4 + i * 2 + 1 ] & 0xFF ) << 8 )); types[i] = getTypeString(data, typeIdx); } return types; } public static String readString (byte [] data, int offset) { int end = offset; while (end < data.length && data[end] != 0 ) { end++; } return new String (data, offset, end - offset, StandardCharsets.UTF_8); } }
field_ids 1 2 3 4 5 struct DexFieldId { u2 classIdx; u2 typeIdx; u4 nameIdx; };
field_ids 表示的是字段信息,指明了字段所在的类,字段的类型以及字段名称,在 DexFile.h 中定义为 DexFieldId , 其各个字段含义如下:
classIdx : 指向 type_ids ,表示字段所在类的信息
typeIdx : 指向 ype_ids ,表示字段的类型信息
nameIdx : 指向 string_ids ,表示字段名称
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 import java.io.FileInputStream;import java.io.IOException;import java.nio.charset.StandardCharsets;public class DexFieldParser { public static void main (String[] args) throws IOException { FileInputStream fis = new FileInputStream ("your.dex" ); byte [] dexData = fis.readAllBytes(); fis.close(); parseFieldIds(dexData); } public static void parseFieldIds (byte [] dexData) { int fieldIdsSize = readInt(dexData, 0x58 ); int fieldIdsOff = readInt(dexData, 0x5C ); System.out.println("Total field_ids: " + fieldIdsSize); for (int i = 0 ; i < fieldIdsSize; i++) { int base = fieldIdsOff + i * 8 ; int classIdx = readU2(dexData, base); int typeIdx = readU2(dexData, base + 2 ); int nameIdx = readInt(dexData, base + 4 ); String classType = getTypeString(dexData, classIdx); String fieldType = getTypeString(dexData, typeIdx); String fieldName = getStringById(dexData, nameIdx); System.out.printf("field[%d]: class=%s, type=%s, name=%s\n" , i, classType, fieldType, fieldName); } } public static int readInt (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public static int readU2 (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ); } public static String getStringById (byte [] data, int stringId) { int stringIdsOff = readInt(data, 0x3C ); int stringDataOff = readInt(data, stringIdsOff + stringId * 4 ); int [] uleb = readUleb128(data, stringDataOff); int stringOffset = stringDataOff + uleb[1 ]; return readString(data, stringOffset); } public static String getTypeString (byte [] data, int typeId) { int typeIdsOff = readInt(data, 0x40 ); int descriptorIdx = readInt(data, typeIdsOff + typeId * 4 ); return getStringById(data, descriptorIdx); } public static String readString (byte [] data, int offset) { int end = offset; while (end < data.length && data[end] != 0 ) { end++; } return new String (data, offset, end - offset, StandardCharsets.UTF_8); } public static int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int shift = 0 ; int b; do { b = data[offset + count] & 0xFF ; result |= (b & 0x7F ) << shift; shift += 7 ; count++; } while ((b & 0x80 ) != 0 ); return new int []{result, count}; } }
method_ids 1 2 3 4 5 struct DexMethodId { u2 classIdx; u2 protoIdx; u4 nameIdx; };
method_ids 指明了方法所在的类、方法声明以及方法名。在 DexFile.h 中用 DexMethodId 表示该项,其属性含义如下:
classIdx : 指向 type_ids ,表示类的类型
protoIdx : 指向 type_ids ,表示方法声明
nameIdx : 指向 string_ids ,表示方法名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 import java.io.FileInputStream;import java.io.IOException;import java.nio.charset.StandardCharsets;public class DexMethodParser { public static void main (String[] args) throws IOException { FileInputStream fis = new FileInputStream ("your.dex" ); byte [] dexData = fis.readAllBytes(); fis.close(); parseMethodIds(dexData); } public static void parseMethodIds (byte [] dexData) { int methodIdsSize = readInt(dexData, 0x60 ); int methodIdsOff = readInt(dexData, 0x64 ); System.out.println("Total method_ids: " + methodIdsSize); for (int i = 0 ; i < methodIdsSize; i++) { int base = methodIdsOff + i * 8 ; int classIdx = readU2(dexData, base); int protoIdx = readU2(dexData, base + 2 ); int nameIdx = readInt(dexData, base + 4 ); String classType = getTypeString(dexData, classIdx); String methodName = getStringById(dexData, nameIdx); String protoDesc = getProtoString(dexData, protoIdx); System.out.printf("method[%d]: class=%s, proto=%s, name=%s\n" , i, classType, protoDesc, methodName); } } public static int readInt (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public static int readU2 (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ); } public static String getStringById (byte [] data, int stringId) { int stringIdsOff = readInt(data, 0x3C ); int stringDataOff = readInt(data, stringIdsOff + stringId * 4 ); int [] uleb = readUleb128(data, stringDataOff); int stringOffset = stringDataOff + uleb[1 ]; return readString(data, stringOffset); } public static String getTypeString (byte [] data, int typeId) { int typeIdsOff = readInt(data, 0x40 ); int descriptorIdx = readInt(data, typeIdsOff + typeId * 4 ); return getStringById(data, descriptorIdx); } public static String getProtoString (byte [] data, int protoId) { int protoIdsOff = readInt(data, 0x44 ); int base = protoIdsOff + protoId * 12 ; int shortyIdx = readInt(data, base); int returnTypeIdx = readInt(data, base + 4 ); int parametersOff = readInt(data, base + 8 ); String returnType = getTypeString(data, returnTypeIdx); StringBuilder params = new StringBuilder (); if (parametersOff != 0 ) { int size = readInt(data, parametersOff); for (int i = 0 ; i < size; i++) { int typeIdx = readU2(data, parametersOff + 4 + i * 2 ); String typeStr = getTypeString(data, typeIdx); params.append(typeStr); if (i != size - 1 ) { params.append(", " ); } } } return "(" + params + ") → " + returnType; } public static String readString (byte [] data, int offset) { int end = offset; while (end < data.length && data[end] != 0 ) { end++; } return new String (data, offset, end - offset, StandardCharsets.UTF_8); } public static int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int shift = 0 ; int b; do { b = data[offset + count] & 0xFF ; result |= (b & 0x7F ) << shift; shift += 7 ; count++; } while ((b & 0x80 ) != 0 ); return new int []{result, count}; } }
class_def 1 2 3 4 5 6 7 8 9 10 struct DexClassDef { u4 classIdx; u4 accessFlags; u4 superclassIdx; u4 interfacesOff; u4 sourceFileIdx; u4 annotationsOff; u4 classDataOff; u4 staticValuesOff; };
class_def 是 DEX 文件结构中最复杂也是最核心的部分,它表示了类的所有信息,对应 DexFile.h 中的 DexClassDef :
classIdx : 指向 type_ids ,表示类信息
accessFlags : 访问标识符
superclassIdx : 指向 type_ids ,表示父类信息
interfacesOff : 指向 DexTypeList 的偏移量,表示接口信息
sourceFileIdx : 指向 string_ids ,表示源文件名称
annotationOff : 注解信息
classDataOff : 指向 DexClassData 的偏移量,表示类的数据部分
staticValueOff :指向 DexEncodedArray 的偏移量,表示类的静态数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 import java.io.FileInputStream;import java.io.IOException;import java.nio.charset.StandardCharsets;public class DexClassDefsParser { public static void main (String[] args) throws IOException { FileInputStream fis = new FileInputStream ("your.dex" ); byte [] dexData = fis.readAllBytes(); fis.close(); parseClassDefs(dexData); } public static void parseClassDefs (byte [] dexData) { int classDefsSize = readInt(dexData, 0x70 ); int classDefsOff = readInt(dexData, 0x74 ); System.out.println("Total class_defs: " + classDefsSize); for (int i = 0 ; i < classDefsSize; i++) { int base = classDefsOff + i * 32 ; int classIdx = readInt(dexData, base); int accessFlags = readInt(dexData, base + 4 ); int superClassIdx = readInt(dexData, base + 8 ); int interfacesOff = readInt(dexData, base + 12 ); int sourceFileIdx = readInt(dexData, base + 16 ); int annotationsOff = readInt(dexData, base + 20 ); int classDataOff = readInt(dexData, base + 24 ); int staticValuesOff = readInt(dexData, base + 28 ); String className = getTypeString(dexData, classIdx); String superClassName = getTypeString(dexData, superClassIdx); String sourceFile = getStringById(dexData, sourceFileIdx); System.out.printf("class[%d]: %s extends %s from [%s], class_data_off=0x%x\n" , i, className, superClassName, sourceFile, classDataOff); } } public static int readInt (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public static String getTypeString (byte [] data, int typeId) { if (typeId < 0 ) return "null" ; int typeIdsOff = readInt(data, 0x40 ); int descriptorIdx = readInt(data, typeIdsOff + typeId * 4 ); return getStringById(data, descriptorIdx); } public static String getStringById (byte [] data, int stringId) { if (stringId < 0 ) return "null" ; int stringIdsOff = readInt(data, 0x3C ); int stringDataOff = readInt(data, stringIdsOff + stringId * 4 ); int [] uleb = readUleb128(data, stringDataOff); int offset = stringDataOff + uleb[1 ]; return readString(data, offset); } public static String readString (byte [] data, int offset) { int end = offset; while (end < data.length && data[end] != 0 ) end++; return new String (data, offset, end - offset, StandardCharsets.UTF_8); } public static int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int shift = 0 ; int b; do { b = data[offset + count] & 0xFF ; result |= (b & 0x7F ) << shift; shift += 7 ; count++; } while ((b & 0x80 ) != 0 ); return new int []{result, count}; } }
DefCLassData 重点是 classDataOff 这个字段,它包含了一个类的核心数据,在 Android 源码中定义为 DexClassData ,它不在 DexFile.h 中了,而是在 DexClass.h 中:
1 2 3 4 5 6 7 struct DexClassData { DexClassDataHeader header; DexField* staticFields; DexField* instanceFields; DexMethod* directMethods; DexMethod* virtualMethods; };
DexClassDataHeader 定义了类中字段和方法的数目,它也定义在 DexClass.h 中:
1 2 3 4 5 6 struct DexClassDataHeader { u4 staticFieldsSize; u4 instanceFieldsSize; u4 directMethodsSize; u4 virtualMethodsSize; };
staticFieldsSize : 静态字段个数
instanceFieldsSize : 实例字段个数
directMethodsSize : 直接方法个数
virtualMethodsSize : 虚方法个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 public class DexClassDataParser { public static void parseClassData (byte [] dexData, int classDataOff) { int staticFieldsSize = readUleb128(dexData, classDataOff)[0 ]; int instanceFieldsSize = readUleb128(dexData, classDataOff + 1 )[0 ]; int directMethodsSize = readUleb128(dexData, classDataOff + 2 )[0 ]; int virtualMethodsSize = readUleb128(dexData, classDataOff + 3 )[0 ]; System.out.println("Static Fields: " + staticFieldsSize); System.out.println("Instance Fields: " + instanceFieldsSize); System.out.println("Direct Methods: " + directMethodsSize); System.out.println("Virtual Methods: " + virtualMethodsSize); int currentOffset = classDataOff + 4 ; for (int i = 0 ; i < staticFieldsSize; i++) { int fieldId = readUleb128(dexData, currentOffset)[0 ]; String fieldName = getFieldName(dexData, fieldId); System.out.println("Static Field [" + i + "]: " + fieldName); currentOffset += 1 ; } for (int i = 0 ; i < instanceFieldsSize; i++) { int fieldId = readUleb128(dexData, currentOffset)[0 ]; String fieldName = getFieldName(dexData, fieldId); System.out.println("Instance Field [" + i + "]: " + fieldName); currentOffset += 1 ; } for (int i = 0 ; i < directMethodsSize; i++) { int methodId = readUleb128(dexData, currentOffset)[0 ]; String methodName = getMethodName(dexData, methodId); System.out.println("Direct Method [" + i + "]: " + methodName); currentOffset += 1 ; } for (int i = 0 ; i < virtualMethodsSize; i++) { int methodId = readUleb128(dexData, currentOffset)[0 ]; String methodName = getMethodName(dexData, methodId); System.out.println("Virtual Method [" + i + "]: " + methodName); currentOffset += 1 ; } } public static int [] readUleb128(byte [] data, int offset) { int result = 0 ; int count = 0 ; int shift = 0 ; int b; do { b = data[offset + count] & 0xFF ; result |= (b & 0x7F ) << shift; shift += 7 ; count++; } while ((b & 0x80 ) != 0 ); return new int []{result, count}; } public static String getFieldName (byte [] dexData, int fieldId) { int fieldIdsOff = readInt(dexData, 0x80 ); int fieldIdOffset = readInt(dexData, fieldIdsOff + fieldId * 4 ); return getStringById(dexData, fieldIdOffset); } public static String getMethodName (byte [] dexData, int methodId) { int methodIdsOff = readInt(dexData, 0x84 ); int methodIdOffset = readInt(dexData, methodIdsOff + methodId * 4 ); return getStringById(dexData, methodIdOffset); } public static int readInt (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } public static String getStringById (byte [] data, int stringId) { if (stringId < 0 ) return "null" ; int stringIdsOff = readInt(data, 0x3C ); int stringDataOff = readInt(data, stringIdsOff + stringId * 4 ); return readString(data, stringDataOff); } public static String readString (byte [] data, int offset) { int end = offset; while (end < data.length && data[end] != 0 ) end++; return new String (data, offset, end - offset, StandardCharsets.UTF_8); } }
继续回到 DexClassData 中来。header 部分定义了各种字段和方法的个数,后面跟着的分别就是 静态字段 、实例字段 、直接方法 、虚方法 的具体数据了。字段用 DexField 表示,方法用 DexMethod 表示。
DexField 1 2 3 4 struct DexField { u4 fieldIdx; u4 accessFlags; };
fieldIdx : 指向 field_ids ,表示字段信息
accessFlags :访问标识符
DexMethod 1 2 3 4 5 struct DexMethod { u4 methodIdx; u4 accessFlags; u4 codeOff; 46 };
method_idx 是指向 method_ids 的索引,表示方法信息。accessFlags 是该方法的访问标识符。codeOff 是结构体 DexCode 的偏移量
DexCode 1 2 3 4 5 6 7 8 9 10 11 12 13 struct DexCode { u2 registersSize; u2 insSize; u2 outsSize; u2 triesSize; u4 debugInfoOff; u4 insnsSize; u2 insns[1 ]; };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 public class DexCodeParser { public static void parseDexCode (byte [] dexData, int codeOffset) { int registersSize = readShort(dexData, codeOffset); int insSize = readShort(dexData, codeOffset + 2 ); int outsSize = readShort(dexData, codeOffset + 4 ); int triesSize = readShort(dexData, codeOffset + 6 ); int debugInfoOffset = readInt(dexData, codeOffset + 8 ); int insnsSize = readInt(dexData, codeOffset + 12 ); byte [] insns = new byte [insnsSize]; System.arraycopy(dexData, codeOffset + 16 , insns, 0 , insnsSize); System.out.println("Registers Size: " + registersSize); System.out.println("Ins Size: " + insSize); System.out.println("Outs Size: " + outsSize); System.out.println("Tries Size: " + triesSize); System.out.println("Debug Info Offset: " + debugInfoOffset); System.out.println("Insns Size: " + insnsSize); for (int i = 0 ; i < insnsSize; i++) { System.out.printf("0x%02X " , insns[i]); if ((i + 1 ) % 16 == 0 ) { System.out.println(); } } System.out.println(); } public static int readShort (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ); } public static int readInt (byte [] data, int offset) { return (data[offset] & 0xFF ) | ((data[offset + 1 ] & 0xFF ) << 8 ) | ((data[offset + 2 ] & 0xFF ) << 16 ) | ((data[offset + 3 ] & 0xFF ) << 24 ); } }
ELF文件结构 参考: https://ctf-wiki.org/executable/elf/structure/basic-info/ https://mp.weixin.qq.com/s/aDbrS_PE_i8Xt7-zZe2v9A
ELF Header 描述了 ELF 文件的概要信息,利用这个数据结构可以索引到 ELF 文件的全部信息,数据结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 typedef struct { unsigned char e_ident[16 ]; uint16_t e_type; uint16_t e_machine; uint32_t e_version; uint64_t e_entry; uint64_t e_phoff; uint64_t e_shoff; uint32_t e_flags; uint16_t e_ehsize; uint16_t e_phentsize; uint16_t e_phnum; uint16_t e_shentsize; uint16_t e_shnum; uint16_t e_shstrndx; } Elf64_Ehdr;
描述进程运行时如何加载 ELF 文件,比如 .text 和 .data 段的位置和权限等。
1 2 3 4 5 6 7 8 9 10 typedef struct { uint32_t p_type; uint32_t p_flags; uint64_t p_offset; uint64_t p_vaddr; uint64_t p_paddr; uint64_t p_filesz; uint64_t p_memsz; uint64_t p_align; } Elf64_Phdr;
Base Address 要计算基地址,首先要确定可加载段中 p_vaddr 最小的内存虚拟地址,之后把该内存虚拟地址缩小为与之最近的最大页面的整数倍即是基地址。根据要加载到内存中的文件的类型,内存地址可能与 p_vaddr 相同也可能不同。
1.在 ELF 的 Program Header 表中查找 p_type == PT_LOAD 的段。
2.确定 最小的 p_vaddr
1 2 3 4 5 6 7 8 9 Elf64_Addr min_vaddr = -1 ; for (int i = 0 ; i < ehdr.e_phnum; ++i) { if (phdr[i].p_type == PT_LOAD) { if (phdr[i].p_vaddr < min_vaddr || min_vaddr == -1 ) { min_vaddr = phdr[i].p_vaddr; } } }
3.向下对齐(align)这个最小地址到页边界 一般都是 0x1000(4096)字节
1 2 #define PAGE_SIZE 0x1000 Elf64_Addr base_vaddr = min_vaddr & ~(PAGE_SIZE - 1 );
4.在动态链接库(.so)或 PIE 文件(ET_DYN 类型)中:
内核会将段加载到任意合适的内存地址上,比如:0x7fabc00000
这个实际加载地址 - base_vaddr 就是我们要补偿的基地址(通常叫 base_address)
1 real_address = base_address + p_vaddr;
如果是非 PIE 的 ET_EXEC 类型,通常 base_address == 0,也就不需要做偏移调整。
p_type
值
宏定义
含义
0PT_NULL忽略
1PT_LOAD可加载段(程序运行所需)
2PT_DYNAMIC动态链接信息段
3PT_INTERP解释器路径(比如 /lib/ld-linux.so.2)
4PT_NOTE各类注解
5PT_SHLIB保留
6PT_PHDR程序头自身所在段
0x6474e550PT_GNU_EH_FRAMEGCC 的异常处理帧表
0x6474e551PT_GNU_STACK栈权限设定段(比如是否允许栈可执行)
描述每个节的名字、类型、偏移、大小等,比如 .text、.data、.symtab、.strtab。
1 2 3 4 5 6 7 8 9 10 11 12 typedef struct { uint32_t sh_name; uint32_t sh_type; uint64_t sh_flags; uint64_t sh_addr; uint64_t sh_offset; uint64_t sh_size; uint32_t sh_link; uint32_t sh_info; uint64_t sh_addralign; uint64_t sh_entsize; } Elf64_Shdr;
详细解释
字段名
说明
sh_name指向节名称字符串表(.shstrtab)的偏移,表示节的名字
sh_type节的类型,常见类型见下方
sh_flags节的属性,比如可写、可执行、可加载(SHF_WRITE, SHF_EXECINSTR, SHF_ALLOC)
sh_addr该节在内存中的地址(如果可加载,否则为 0)
sh_offset该节在文件中的偏移(用于读取节内容)
sh_size节的字节大小
sh_link依节类型而定,例如 .symtab 的 link 指向 .strtab(字符串表)
sh_info附加信息,如 .symtab 中表示本地符号数量
sh_addralign对齐值(2 的幂),决定节在内存/文件中对齐边界
sh_entsize如果节是一个“表”,这个字段表示每项的大小(如 .symtab 中一个符号的大小)
sh_type
值
名称
说明
0SHT_NULL无效节头(第一个节保留)
1SHT_PROGBITS普通数据,比如 .text, .data
2SHT_SYMTAB符号表
3SHT_STRTAB字符串表
4SHT_RELA有符号重定位表
5SHT_HASH哈希表
6SHT_DYNAMIC动态链接信息表
7SHT_NOTE标注节(比如编译器信息)
8SHT_NOBITS不占文件空间的节(如 .bss)
9SHT_REL无偏移重定位表
0x0bSHT_DYNSYM动态符号表
sh_flags
标志名
值
说明
SHF_WRITE0x1节可写
SHF_ALLOC0x2节会被加载进内存
SHF_EXECINSTR0x4节包含可执行指令
SHF_MERGE0x10内容可以合并(字符串表等)
SHF_STRINGS0x20节包含 null 结尾的字符串
SHF_INFO_LINK0x40sh_info 字段与其他节有关
SHF_TLS0x400节用于线程本地存储
Program Header(段)
Section Header(节)
操作系统加载用
链接器/调试器用
每段可以包含多个节
更细粒度的代码/数据划分
用于加载运行时内容
用于描述文件内容结构
段的对齐、权限等更重要
节名、调试、符号、重定位等更丰富
Smali汇编 基本类型 Smali基本数据类型中包含两种类型,原始类型和引用类型。对象类型和数组类型是引用类型,其它都是原始类型。具体数据类型如下表所示。
Smali Java 说明
v
void
只能用于返回值类型
Z
boolean
布尔类型
B
byte
字节类型
S
short
短整型
C
char
字符型
I
int
整数类型
J
long
长整型
F
float
浮点型数据类型
D
double
双精度浮点型
Lpackage/name;
对象类型
L接完整的包名,使用“;”表示对象名称的结束
[数据类型
数组
[Ljava/lang/String,表示一个String类型的数组
类的定义 示例
1 2 3 public class Test implements CharSequence { }
1 2 3 4 .class public LTest; #声明类(不可省略) .super Ljava/lang/Object; #声明该类所继承的父类,同Java,若没有指定其他父类,则所有类的父类都是Object(不可省略) .implements Ljava /lang/CharSequence; #若该类实现了接口,则添加该代码(视情况可省略) .source "Test.java" #反编译的过程中自动生成的标识该smali类对应的java源码类的标识,无实际作用(可省略)
函数声明 1 2 3 .method 权限修饰符+静态修饰符+方法名(参数类型)返回值类型 #方法体 .end method
示例1
1 2 3 4 public class Test { public static void getName () {} }
1 2 3 4 5 6 7 .class public LTest; .super Ljava/lang/Object; .source "Test.java" .method public static getName () V return -void .end method
示例2(带返回值)
1 2 3 4 5 6 public class Test { public static String getName (String a,int b) { return "hello" } }
1 2 3 4 5 6 7 8 .class public LTest; .super Ljava/lang/Object; .source "Test.java" .method public static getName (Ljava/lang/String;I) Ljava/lang/String; const-string v0, "hello" return -object v0 .end method
函数返回关键字
Smali方法返回关键字 J数据类型
return
byte
return
short
return
int
return
float
return
char
return
boolean
return-wide
double
return-wide
long
return-void
void
return-object
array
return-object
object
smali中总共分为四种函数返回关键字,对于不同的数据类型,使用不同的函数返回关键字,long、double为64位数据类型,因此需要使用return-wide关键字,而其他基本数据类型为32位及以下,只需要使用return。对于空类型使用return-void。而对于大小未知的数组及object,则使用return-object。
构造函数声明 1 2 3 .method+权限修饰符+constructor <init>(参数类型)返回值类型 #方法体 .end method
示例
1 2 3 4 5 public class Test { public Test (String a) { } }
1 2 3 4 5 6 7 8 .class public LTest; .super Ljava/lang/Object; .source "Test.java" .method public constructor <init>(Ljava/lang/String;)V invoke-direct {p0},Ljava/lang/Object;-><init>()V #调用父类(Object)的构造函数 return -void .end method
构造函数的声明与普通函数声明的区别在于:1.必须加constructor修饰符;2.函数名必须为<init>;3.函数中必须调用父类的构造函数(java的构造函数中默认会调用父类的构造函数,但在代码中可以省略,而在Smali中不能省略)。
变量声明 1 .field 权限修饰符+静态修饰符+变量名:变量全类名路径;
1 2 3 4 public class Test { private static String a; }
1 2 3 4 5 .class public LTest; .super Ljava/lang/Object; .source "Test.java" .field private static a:Ljava/lang/String; #声明一个String类的对象,命名为a
常量声明 1 .field 权限修饰符+静态修饰符+final +常量名:常量全类名路径;=常量值
1 2 3 4 public class Test { private static final String a="hello" ; }
1 2 3 4 5 .class public LTest; .super Ljava/lang/Object; .source "Test.java" .field private static final a:Ljava/lang/String;="hello" #声明一个String类的常量对象,命名为a,赋值为"hello"
静态代码块 1 2 3 .method+static +constructor <clinit>()V #方法体 .end method
1 2 3 4 public class Test { static {} }
1 2 3 4 5 6 .class public LTest; .super Ljava/lang/Object; .method public static constructor<clinit>()V return -void .end method
静态代码块的声明同构造函数的声明的区别在于:1.增加了static修饰符;2.函数名改为了<clinit>;3.无参数;4.返回类型固定为void
Smali静态字段声明位置
1 2 3 4 5 public class Test { public static String a="a" ; static {} }
1 2 3 4 5 6 7 .class public LTest; .super Ljava/lang/Object; .method public static constructor<clinit>()V .field public static a:Ljava/lang/String;="a" return -void .end method
当类中声明了静态的字段时,该字段的声明必须于静态代码块中进行,因该字段属于类而非对象,且静态代码块在构造函数之前被执行。
函数调用 1 2 3 4 5 invoke-virtual #非私有实例函数的调用 invoke-direct #构造函数以及私有函数的调用 invoke-static #静态函数的调用 invoke-super #父类函数的调用 invoke-interface #接口函数的调用
示例
1 2 3 4 5 6 7 8 9 public class Test { public Test (String a) { getName(); } public String getName () { return "hello" ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 .class public LTest; .super Ljava/lang/Object; .method public constructor<init>(Ljava/lang/String;)V invoke-direct{p0},Ljava/lang/Object;-><init>()V #调用父类的构造函数 invoke-virtual{p0},LTest;->getName()Ljava/lang/String; #调用普通成员getName函数 return -void .end method .method public getName () Ljava/lang/String; const-string v0,"hello" #定义局部字符串常量 return -object v0 #返回常量 .end method
以上代码段中定义的getName函数是没有参数的,但是在调用该函数时却传入了一个参数p0,该p0参数实质上为类的对象,即java中的this。因被调用的getName函数非静态函数,因此在使用该函数时必须传入一个this作为参数,而这一步在java中被默认执行,故书写代码时常被省略。
示例:构造函数以及私有实例函数的调用
1 invoke-direct {参数},函数所属类名;->函数名(参数类型)返回值类型;
1 2 3 4 5 6 7 8 9 public class Test { public Test (String a) { getName(); } private String getName () { return "hello" ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 .class public LTest; .super Ljava/lang/Object; .method public constructor<init>(Ljava/lang/String;)V invoke-direct{p0},Ljava/lang/Object;-><init>()V #调用父类的构造函数 invoke-direct{p0},LTest;->getName()Ljava/lang/String; #调用私有成员getName函数 return -void .end method .method private getName () Ljava/lang/String; const-string v0,"hello" #定义局部字符串常量 return -object v0 #返回常量 .end method
示例:静态函数
1 invoke-static {参数},函数所属类名;->函数名(参数类型)返回值类型;
1 2 3 4 5 6 7 8 9 public class Test { public Test (String a) { String b=getName(); } private static String getName () { return "hello" ; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 .class public LTest; .super Ljava/lang/Object; .method public constructor<init>(Ljava/lang/String;)V invoke-direct{p0},Ljava/lang/Object;-><init>()V #调用父类的构造函数 invoke-static {},LTest;->getName()Ljava/lang/String; #调用私有成员getName函数 move-result-object v0 #将返回值赋给v0 return -void .end method .method private getName () Ljava/lang/String; const-string v0,"hello" #定义局部字符串常量 return -object v0 #返回常量 .end method
示例: 父类成员函数的调用
1 invoke-super {参数},函数所属类名;->函数名(参数类型)返回值类型;
1 2 3 4 @Override protected void onCreate (Bundle savedInstanceState) { super .onCreate(savedInstanceState); }
1 2 3 4 5 6 .method protected onCreate (Landroid/os/Bundle;) V .registers 2 invoke-super {p0,p1},Landroid/app/Activity;->onCreate(Landroid/os/Bundle;)V return -void .end method
示例: 接口函数调用
1 invoke-interface {参数},函数所属类名;->函数名(参数类型)返回值类型;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class Test { private InterTest a=new Test2 (); public Test (String a) {} public void setAa () { InterTest aa=a; aa.est2(); } public class Test2 implements InterTest { public Test2 () {} public void est2 () {} } interface InterTest { public void est2 () ; } }
1 2 3 4 5 6 7 .method public setAa () V .registers 2 iget-object v0,p0,LTest;->a:LTest$InterTest; #调用接口方法 invoke-interface{v0},LTest$InterTest;->est2()V return -void .end method
字段取值与赋值 1 2 3 4 iput 存储值的寄存器,对象全类名路径->字段名:字段类型全类名路径 #静态字段 iput 存储值的寄存器,存储字段的对象,对象全类名路径->字段名:字段类型全类名路径 #字段 iget 存储值的寄存器,对象全类名路径->字段名:字段类型全类名路径 #静态字段 iget 存储值的寄存器,对象全类名路径->字段名:字段类型全类名路径 #字段
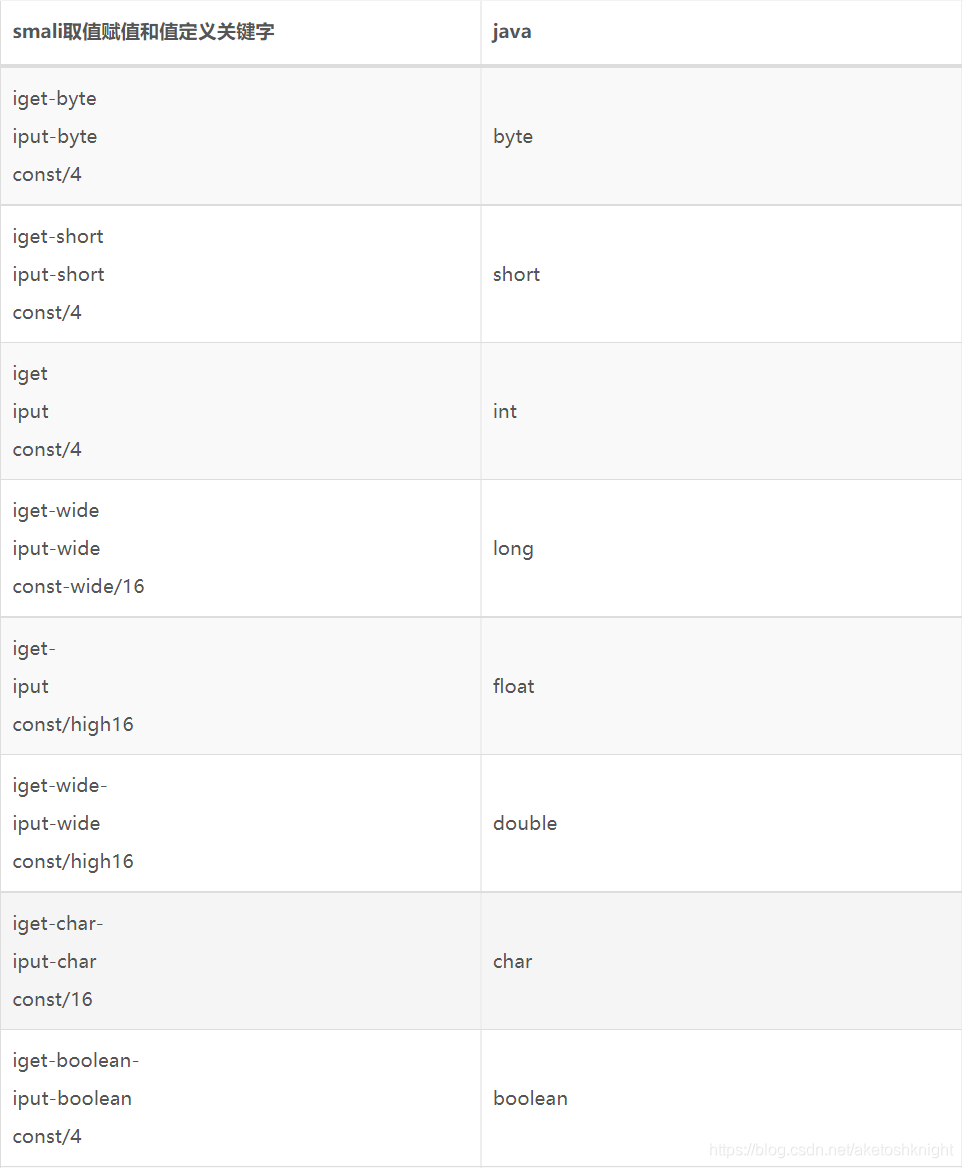
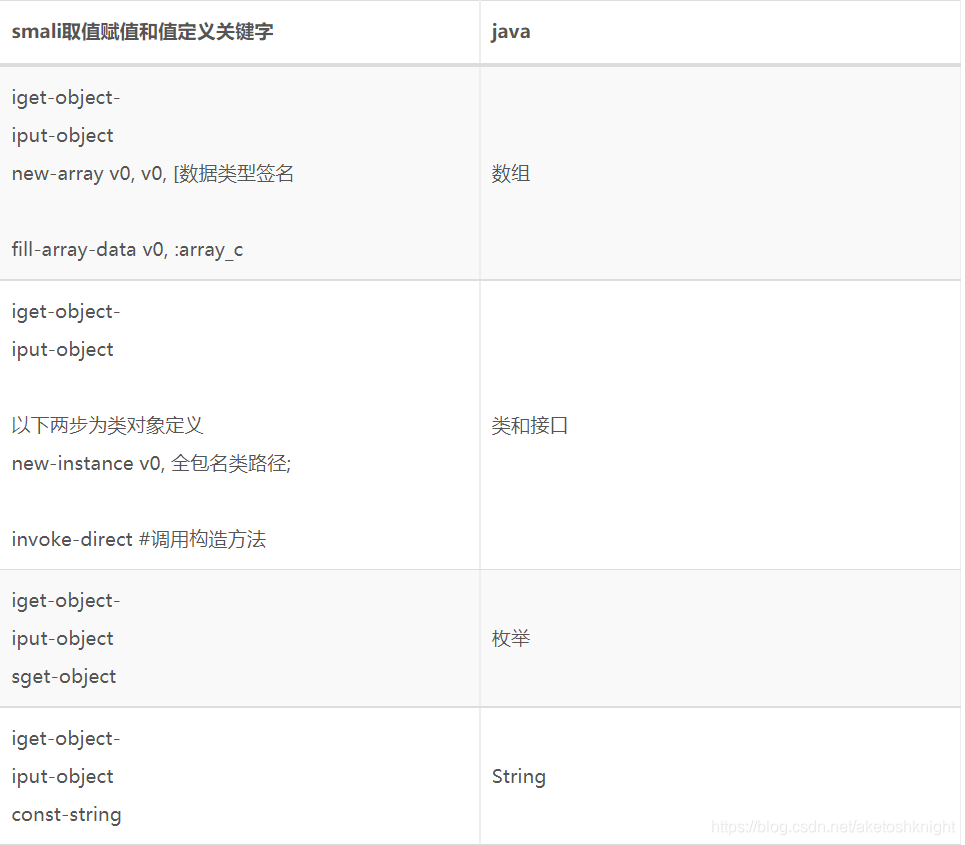
Smali基本数据类型取值赋值关键字表
Smali实例变量取值赋值关键字表
smali——java取值赋值对照
1 2 3 4 5 6 7 8 9 public class Test { private String a="hello" ; public Test (String a) { } public String getA () { String aa=a; } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 .class public LTest;#声明类 (必须) .super Ljava/lang/Object;#声明父类 默认继承Object (必须) .source "Test.java" # 源码文件 (非必须) # 声明静态字段 .field private static a:Ljava/lang/String; #构造方法 .method public constructor <init>(Ljava/lang/String;)V .registers 3 .prologue invoke-direct {p0}, Ljava/lang/Object;-><init>()V const-string v0, "hello" # 初始化成员变量 iput-object v0, LTest;->a:Ljava/lang/String; return -void .end method # 取值方法 .method public getA () Ljava/lang/String; .registers 2 # 类非静态字段取值 iget-object v0, LTest;->a:Ljava/lang/String; return -object v0 .end method
Smali数组的取值与赋值 1 2 aput 存储值的寄存器,存储数组的寄存器,存储数组下标的寄存器 aget 存储值的寄存器,存储数组的寄存器,存储数组下标的寄存器
示例
1 2 3 4 5 6 invoke-virtual {v1, v0}, Ljava/security/MessageDigest;->digest([B)[B move-result-object v0 const/16 v4,47 const/16 v5,0 aput-byte v4,v0,v5 aget-byte v3,v0,v5
这里解释下这段汇编
invoke-virtual {v1, v0}, Ljava/security/MessageDigest;->digest([B)[B
调用 Java 的 MessageDigest.digest(byte[] input) 方法。
v1:MessageDigest 实例(如 SHA-256)
v0:原始输入的 byte[]
返回值是 byte[] 类型,存储计算后的哈希值。
move-result-object v0
接收上一步调用返回的哈希结果,赋值给 v0。
此时,v0 成为了 digest 输出的 byte[]。
const/16 v4, 47
将整数常量 47 加载到 v4 中。
十进制 47 = 十六进制 0x2F,等于 ASCII 字符 '/'。
const/16 v5, 0
将索引值 0 加载到 v5 中,用于访问 v0 数组的第一个元素
aput-byte v4, v0, v5
将 v4(即 47)这个字节写入到 v0[0] 中。
相当于强行篡改哈希结果的首字节:
aget-byte v3, v0, v5
Smali对象创建 定义
1 2 new -instance+对象名,对象全包名路径; #声明实例invoke-direct{变量名},对象全包名路径;-><init>(参数)返回类型 #调用构造函数(若构造函数内还定义了成员变量,则在调用之前需要提前声明该变量并在invoke时作为参数一并传入)
示例
1 2 new -instance v0,LTest;invoke-direct {v0},LTest;-><init>()V
Smali常量数据定义 定义: 在Smali语言中,函数返回或函数调用等处若需使用常量,应当如同使用变量一般先行将之定义并存入寄存器中,后方可使用。
Smali字符串常量定义 定义
1 const-string 常量名,"字符串内容"
示例
1 2 3 4 5 6 7 8 .class public LTest; .super Ljava/lang/Object; .method public static getHello () Ljava/lang/String; .registers 1 #该函数总共使用了1 个寄存器 const-string v0,"hello" #定义字符串常量 return -object v0 #将字符串常量作为返回值 .end method
如上代码段所示,定义一个”hello”字符串存入寄存器,命名为v0,并将之作为返回值返回(因字符串为Object类型的数据,因此使用return-object)
Smali字节码常量定义 定义
示例
1 const-class v0 ,LTestClass;
Smali数值常量定义 格式
1 2 3 4 5 6 7 8 9 10 const 寄存器,数值 #占用一个寄存器(32位) const/4 #占用一个寄存器中的低4位(最高位为符号位) const/16 #占用一个寄存器中的低16位(最高位为符号位) const #占用一个寄存器中全部32位(最高位为符号位) const/high16 #占用一个寄存器中的16位,且只将数据的高16位存入(最高位为符号位) const-wide 寄存器,数值 #占用两个寄存器(64位) const-wide/16 #占用两个寄存器的同时只使用第一个寄存器的低16位 const-wide/32 #占用两个寄存器的同时只使用第一个寄存器的32位 const-wide #占用两个寄存器的同时只使用两个寄存器的全部64位 const-wide/high16 #占用两个寄存器的同时只使用第一个寄存器的16位,且只将数据的高16位存入
示例
1 2 int i=100 ;long j=10000 ;
1 2 const/16 v0,64 const-wide v1,2710
Smali条件跳转 定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 if -eq vA, vB, :cond_** #如果vA等于vB则跳转到:cond_** equal if -ne vA, vB, :cond_** #如果vA不等于vB则跳转到:cond_** not equal if -lt vA, vB, :cond_** #如果vA小于vB则跳转到:cond_** less than if -ge vA, vB, :cond_** #如果vA大于等于vB则跳转到:cond_** greater equal if -gt vA, vB, :cond_** #如果vA大于vB则跳转到:cond_** greater than if -le vA, vB, :cond_** #如果vA小于等于vB则跳转到:cond_** less equal if -eqz vA, :cond_** #如果vA等于0 则跳转到:cond_** zeroif -nez vA, :cond_** #如果vA不等于0 则跳转到:cond_**if -ltz vA, :cond_** #如果vA小于0 则跳转到:cond_**if -gez vA, :cond_** #如果vA大于等于0 则跳转到:cond_**if -gtz vA, :cond_** #如果vA大于0 则跳转到:cond_**if -lez vA, :cond_** #如果vA小于等于0 则跳转到:cond_**
示例
1 2 3 4 5 6 7 8 public class Test { public static void main (String[] args) { int a=2 ; if (a>1 ){ } } }
1 2 3 4 5 6 7 8 9 .method public static main ([Ljava/lang/String;) V const/16 v0,0x2 const/4 v1, 0x1 if -le v0,v1,:cond_0 #do -something :cond_0 return -void .end method
Smali逻辑循环 定义
1 goto :cond_** #跳转到:cond_**
示例
1 2 3 4 5 6 7 public class Test { public static void main (String[] args) { for (int i=0 ; i<3 ;i++){ } } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 .method public static main ([Ljava/lang/String;) V const/4 v0, 0x0 :goto_1 const/4 v1, 0x3 if -ge v0, v1, :cond_7 add-int /lit8 v0, v0, 0x1 # 加法运算符 v0=v0+0x1 goto :goto_1 :cond_7 return -void .end method
寄存器 寄存器分为如下两类:
ARM汇编 具体参考: https://blog.csdn.net/Luckiers/article/details/128221506
寄存器详解 1. 通用寄存器 通用寄存器是一组用于存储数据和地址的寄存器。在 ARM 架构 的不同版本中,这些寄存器的数量和命名有所不同。
X0-X30 (X0-X28+ FR + LR):
在ARMv7架构中使用程序状态寄存器(Current Program Status Register,CPSR)来表示当前的处理器状态(processor stste),而在ARMv8里使用PSTATE寄存器来表示。
ARMv8及以后版本:
寄存器
位数
描述
X0-X30
64bit
通用寄存器,如果有需要可以当作32bit使用:W0-W30
FP(X29)
64bit
保存栈帧地址(栈底指针)
LR(X30)
64bit
程序链接寄存器,保存子程序结束后需要执行的下一条指令
SP
64bit
保存栈顶指针,使用SP/WSP来进行对SP寄存器的访问。
PC
64bit
程序计数器,俗称PC指针,总是指向即将要执行的下一条指令,在arm64中,软件不能修改PC寄存器
PSTATE
64bit
状态寄存器,用于保存处理器的当前状态信息。
ARM 64包含31个64bit寄存器,记为X0X30。W30。
LDR和STR分别从地址中读入内容到寄存器和向地址中写入寄存器的内容,后缀B表示字节,H表示半字,W表示单字
向量和浮点寄存器。32个寄存器,向量和浮点共用,每个128位,用V0到V31来表示。不同的记号可以表示不同的长度,B表示字节,H表示半字,S表示单字,D表示双字,Q表示四字
X0 - X7: 这8个寄存器通常用作函数参数寄存器,在函数调用时用来传递前8个参数,若参数个数大于8,就采用栈来传递。64位的函数返回值通常存放在X0寄存器中,128位的返回结果存在X0和X1两个寄存器中。
X18: X18 (Platform register)这个寄存器通常被用作平台相关的寄存器,其用途取决于具体的硬件平台和软件环境。在某些系统中,X18 可能被用作过程链接表(PLT)指针,用于动态链接。在其他系统中,X18 可能被用作线程局部存储(Thread Local Storage)的指针。
X29: Frame Pointer (FP) 寄存器,它的主要作用是指向当前函数的栈帧(Stack Frame),方便访问函数内部的局部变量和参数。当一个函数被调用时,x29 寄存器会被设置为指向该函数的栈帧起始地址。这样可以通过 x29 寄存器轻松访问函数内部的局部变量和参数,而不需要依赖 x30 寄存器(Link Register)中存储的返回地址。
X30: Link Register (LR),它的主要作用是在函数调用时存储函数的返回地址,以便函数执行完毕后能够正确地返回到调用点。当一个函数被调用时,CPU 会将当前执行点的地址保存到 x30 寄存器中。这样在函数执行完毕后,只需要从 x30 寄存器中恢复返回地址,就可以正确地返回到调用点。注意:当一个函数被调用时,CPU 会自动将当前执行点的地址(也就是函数调用语句的下一条指令地址)保存到 x30 寄存器中。
X9 - X15和X19 - X28这两组寄存器的区别:
x9 到 x15 则主要用作临时变量和中间计算结果的存储。x19 到 x28 通常用作函数的局部变量和中间计算结果的存储。对于 x9 到 x15 这些”caller-saved”寄存器,调用者(caller)有责任在函数调用前保存它们的值,并在调用后恢复。对于 x19 到 x28 这些”callee-saved”寄存器,被调用的函数(callee)有责任在返回前保存和恢复它们的值。使用”callee-saved”寄存器通常可以减少对栈的访问,提高性能。但同时也增加了函数调用时保存和恢复寄存器的开销。
ARMv8前版本:
2. 专用寄存器 ARM处理器中的专用寄存器主要包括程序状态寄存器(CPSR)和备份的程序状态寄存器(SPSRs)。
CPSR是一个32位的特殊寄存器,用于存储当前程序的状态信息。它包含以下内容:
ALU状态标志 :如条件码(如零标志Z、负标志N、进位标志C等),用于反映ALU的运算结果。
CPSR和SPSR都是程序状态寄存器,其中SPSR是用来保存中断前的CPSR中的值,以便在中断返回之后恢复处理器程序状态。
ARM处理器还包含5个备份的程序状态寄存器(SPSR_fiq、SPSR_irq、SPSR_svc、SPSR_abt、SPSR_und),用于在异常处理期间保存CPSR的值。当处理器进入异常模式时,会将CPSR的内容复制到对应的SPSR中;当从异常模式返回时,则可以将SPSR的内容复制回CPSR以恢复处理器的状态。
3. 控制寄存器 虽然控制寄存器不直接归类为通用或专用寄存器,但它们在ARM处理器的控制中发挥着重要作用。这些寄存器通常包含处理器的控制位和配置位,用于控制处理器的行为和工作模式。由于控制寄存器的访问和修改通常需要特权级代码,因此它们在普通的应用程序中很少被直接访问。如控制CPU的行为,如 CTRL 和 ACTLR。
2.1 32位数据操作指令
名字
功能
ADC
带进位加法
ADD
加法
ADDW
宽加法(可以加 12 位立即数)
AND
按位与
ASR
算术右移
BIC
位清零(把一个数按位取反后,与另一个数逻辑与)
BFC
位段清零
BFI
位段插入
CMN
负向比较(把一个数和另一个数的二进制补码比较,并更新标志位)
CMP
比较两个数并更新标志位
CLZ
计算前导零的数目
EOR
按位异或
LSL
逻辑左移
LSR
逻辑右移
MLA
乘加
MLS
乘减
MOVW
把 16 位立即数放到寄存器的底16位,高16位清0
MOV
加载16位立即数到寄存器(其实汇编器会产生MOVW——译注)
MOVT
把 16 位立即数放到寄存器的高16位,低 16位不影响
MVN
移动一个数的补码
MUL
乘法
ORR
按位或
ORN
把源操作数按位取反后,再执行按位或(
RBIT
位反转(把一个 32 位整数先用2 进制表达,再旋转180度——译注)
REV
对一个32 位整数做按字节反转
REVH/REV16
对一个32 位整数的高低半字都执行字节反转
REVSH
对一个32 位整数的低半字执行字节反转,再带符号扩展成32位数
ROR
圆圈右移
RRX
带进位的逻辑右移一格(最高位用C 填充,且不影响C的值——译注)
SFBX
从一个32 位整数中提取任意的位段,并且带符号扩展成 32 位整数
SDIV
带符号除法
SMLAL
带符号长乘加(两个带符号的 32 位整数相乘得到 64 位的带符号积,再把积加到另一个带符号 64位整数中)
SMULL
带符号长乘法(两个带符号的 32 位整数相乘得到 64位的带符号积)
SSAT
带符号的饱和运算
SBC
带借位的减法
SUB
减法
SUBW
宽减法,可以减 12 位立即数
SXTB
字节带符号扩展到32位数
TEQ
测试是否相等(对两个数执行异或,更新标志但不存储结果)
TST
测试(对两个数执行按位与,更新标志但不存储结果)
UBFX
无符号位段提取
UDIV
无符号除法
UMLAL
无符号长乘加(两个无符号的 32 位整数相乘得到 64 位的无符号积,再把积加到另一个无符号 64位整数中)
UMULL
无符号长乘法(两个无符号的 32 位整数相乘得到 64位的无符号积)
USAT
无符号饱和操作(但是源操作数是带符号的——译注)
UXTB
字节被无符号扩展到32 位(高24位清0——译注)
UXTH
半字被无符号扩展到32 位(高16位清0——译注)
2.2 32位存储器数据传送指令
名字
功能
LDR
加载字到寄存器
LDRB
加载字节到寄存器
LDRH
加载半字到寄存器
LDRSH
加载半字到寄存器,再带符号扩展到 32位
LDM
从一片连续的地址空间中加载多个字到若干寄存器
LDRD
从连续的地址空间加载双字(64 位整数)到2 个寄存器
STR
存储寄存器中的字
STRB
存储寄存器中的低字节
STRH
存储寄存器中的低半字
STM
存储若干寄存器中的字到一片连续的地址空间中
STRD
存储2 个寄存器组成的双字到连续的地址空间中
PUSH
把若干寄存器的值压入堆栈中
POP
从堆栈中弹出若干的寄存器的值
2.3 32位转移指令
名字
功能
B
无条件转移
BL
转移并连接(呼叫子程序)
TBB
以字节为单位的查表转移。从一个字节数组中选一个8位前向跳转地址并转移
TBH
以半字为单位的查表转移。从一个半字数组中选一个16 位前向跳转的地址并转移
2.4 其它32位指令
名字
功能
LDREX
加载字到寄存器,并且在内核中标明一段地址进入了互斥访问状态
LDREXH
加载半字到寄存器,并且在内核中标明一段地址进入了互斥访问状态
LDREXB
加载字节到寄存器,并且在内核中标明一段地址进入了互斥访问状态
STREX
检查将要写入的地址是否已进入了互斥访问状态,如果是则存储寄存器的字
STREXH
检查将要写入的地址是否已进入了互斥访问状态,如果是则存储寄存器的半字
STREXB
检查将要写入的地址是否已进入了互斥访问状态,如果是则存储寄存器的字节
CLREX
在本地的处理上清除互斥访问状态的标记(先前由 LDREX/LDREXH/LDREXB做的标记)
MRS
加载特殊功能寄存器的值到通用寄存器
MSR
存储通用寄存器的值到特殊功能寄存器
NOP
无操作
SEV
发送事件
WFE
休眠并且在发生事件时被唤醒
WFI
休眠并且在发生中断时被唤醒
ISB
指令同步隔离(与流水线和 MPU等有关——译注)
DSB
数据同步隔离(与流水线、MPU 和cache等有关——译注)
DMB
数据存储隔离(与流水线、MPU 和cache等有关——译注)
DMB
数据存储器隔离。DMB 指令保证: 仅当所有在它前面的存储器访问操作都执行完毕后,才提交(commit)在它后面的存储器访问操作。
DSB
数据同步隔离。比 DMB 严格: 仅当所有在它前面的存储器访问操作都执行完毕后,才执行在它后面的指令(亦即任何指令都要等待存储器访 问操作——译者注)
ISB
指令同步隔离。最严格:它会清洗流水线,以保证所有它前面的指令都执行完毕之后,才执行它后面的指令。
2.5 立即数 1、立即数:一个立即数是一块数据存储作为指令本身,而不是在一个中的一部分内容存储器位置或寄存器。立即值通常用于加载值或对常量执行算术或逻辑运算的指令。
2.6 逻辑数 逻辑数是用来表示二值逻辑中的”是”与”否”、或称”真”与”假”两个状态的数据。在计算机中,可以用一位基2码表示逻辑数据,即8个逻辑数据可以存放在1个字节中,可用其中的每个bit(位)表示一个逻辑数据。逻辑数可以用计算机中的基2码的两个状态”1”和”0”来表示,其中”1”表示真,”0”表示假。
2.7 逻辑运算和算术运算 逻辑运算是一种只存在于二进制中的运算。在计组中逻辑运算经常出现的是 或、与、非和异或,这几种运算方式。
实例讲解 3.1 MRS 将状态寄存器CPSR或SPSR的内容移动到一个通用寄存器
3.2 MSR 将立即数或通用寄存器的内容加载到CPSR或SPSR的指定字段中
1 2 3 MSR CPSR,R0 MSR SPSR,R0 MSR CPSR_c,R0
3.3 PRIMASK 用于disable NMI和硬 fault之外的所有异常,它有效地把当前优先级改为 0(可编程 优先级中的最高优先级)。
A:表示启用或禁止不精确的中止;I:表示启用或禁止IRQ中断;F:表示启用或禁止FIQ中断
3.4 FAULTMASK 1 2 3 CPSIE f; / CPSID f; MSR FAULTMASK,R0
FAULTMASK更绝,它把当前优先级改为-1。这么一来,连硬fault都被掩蔽了。使用方案与
3.5 BX指令 BX{条件} 目标地址
3.6 零寄存器 wzr、xzr 因为我们在使用 str 的是没法使用立即数 0 给寄存器赋值,所以 wzr xzr就是干这个事情的。是一个比较特殊又常常见到的寄存器。
3.7 立即寻址指令MOV 1 2 3 4 SUBS R0,R0,#1 MOV R0,#0xFF000 MOV R1,R2 SUB R0,R1,R2
3.8 寄存器间接寻址指令LDR 1 2 LDR R1,[R2] SWP R1,R1,[R2]
1 2 3 4 5 6 按照从简单到复杂的分类方法,可以通过以下方式来指定访存指令的地址:从寄存器中获取地址;通过寄存器内容再加上偏移来获取地址;对偏移进行扩展、移位等运算之后,再与寄存器内容相加,获得地址。 LDR X0, [X1] ; 直接从寄存器X1的内容中获取地址。 LDR X0, [X1, LDR X0, [X1, X2] ; X!的内容和X2的内容相加得到地址。 LDR X0, [X1, W2, SXTW] ; 对W2的内容做符号扩展,再与X1的内容相加,作为地址。 LDR X0, [X1, X2, LSL
3.9 寄存器移位寻址指令LSL 1 2 MOV R0,R2,LSL #3 ANDS R1,R1,R2,LSL R3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 寻址模式 简单模式:X1的内容不会被改变,例如。 LDR X0, [X1] LDR X0, [X1, #4] 前变址模式,X1的内容在load之前变化,例如。 LDR X0, [X1, #4]! 等价于 ADD X1, X1, #4 LDR X0, [X1] 后变址模式,X1的内容在load之后变化,例如。 LDR X0, [X1], #4 等价于 LDR X0, [X1] ADD X1, X1, #4 支持对整型、浮点标量和向量,要求源寄存器和目的寄存器必须具有相同的宽度,例如。 LDP W3, W7, [X0] ; [X0] => W3, [X0 + 4 bytes] =>W7 STP Q0, Q1, [X4] ; Q0 => [X4], Q1=>[X4 + 16 bytes]
3.10 基址寻址指令 STR 1 2 LDR R2,[R3,#0x0C] STR R1,[R0,#-4]!
3.11 多寄存器寻址指令 1 2 LDMIA R1!,{R2-R7,R12} STMIA R0!,{R2-R7,R12}
3.12 无条件转移B,BAL 举例: B LABEL ; LABEL为某个位置
1 2 CMP x3,x4 B.CS {pc}+0x10 ; 0xc000800094
BCC是指CPSR寄存器条件标志位为0时的跳转。结合CMP R3, R1,意思是比较R3 R1寄存器,当相等时跳转到环测试。因为CMP指令减去两个值并在CPSR中设置条件标志位。
3.13 条件转移B.cont 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 BEQ 相等 BNE 不等 BPL 非负 BMI 负 BCC 无进位 BCS 有进位 BLO 小于(无符号数) BHS 大于等于(无符号数) BHI 大于(无符号数) BLS 小于等于(无符号数) BVC 无溢出(有符号数) BVS 有溢出(有符号数) BGT 大于(有符号数) BGE 大于等于(有符号数) BLT 小于(有符号数) BLE 小于等于(有符号数)
1 2 3 blr Xm:跳转到由Xm目标寄存器指定的地址处,同时将下一条指令存放到X30寄存器中。例如:blr x20. br Xm:跳转到由Xm目标寄存器指定的地址处。不是子程序返回 ret {Xm}:跳转到由Xm目标寄存器指定的地址处。是子程序返回。Xm可以不写,默认是X30.
3.14 WFE 和 WFI 对比 wfi 和 wfe 指令都是让ARM核进入standby睡眠模式。wfi是直到有wfi唤醒事件发生才会唤醒CPU,wfe是直到wfe唤醒事件发生,这两类事件大部分相同。唯一不同之处在于wfe可以被其他CPU上的sev指令唤醒,sec指令用于修改event寄存器的指令。
WFE
SEV
3.15 MRC:协处理器寄存器到ARM寄存器的数据传输 MRC指令将协处理器的寄存器中数值传送到ARM处理器的寄存器中。如果协处理器不能成功地执行该操作,将产生未定义的指令异常中断。
1 2 MRC p2,5,r3,c5,c6协处理器p2把c5和c6经过5操作的结果赋给r3 MRC p3,9,r3,c5,c6,2协处理器p3把c5和c6经过9操作(类型2)的结果赋给r3
3.16 MCR:寄存器到协处理器寄存器的数据传输 MCR指令将ARM处理器的寄存器中的数据传送到协处理器的寄存器中。如果协处理器不能成功地执行该操作,将产生未定义的指令异常中断。
1 MCR p6,0,r4,c5,c6协处理器p6把r4执行0操作后将结果存放进c5
3.17 STM:将指令中寄存器列表中的各寄存器数值写入到连续的内存单元中 STM指令是Store Multiple的缩写,它的作用是将多个寄存器的值保存到栈中。在ARM汇编中,栈是一种后进先出 (LIFO)的数据结构,用来存储临时数据和函数调用过程中的返回地址
STM指令的语法如下:
其中,条件码是可选项,用来指定条件执行STM指令的条件;模式用来指定存储模式,
1、寻址模式(mode)
常用的模式有IA (递增后存储) 、IB (递增前存储) 、DA (减后存储)和DB(递减前存储);SP是栈指针寄存器,用来指定栈的起始地址;寄存器列表指定要保存的寄存器。
在上述代码中,STMFD指令存储了RO、R1和R2的值到栈中。SP!表示栈指针寄存器递增,即存储完后栈指针自动增加,以便下一次保存操作。
2、“!”
3、“^”
在数据传输完成后,将SPSR的值复制到CPSR中,常用于异常模式下的返回.
3.18 LDM:将数据从连续内存单元中读取到指令的寄存器列表中的各寄存器中 LDMIA
3.19 LDR:从内存中将一个32位的字读取到目标寄存器 1 ldr 加载指令: LDR{条件} 目的寄存器,<存储器地址>
LDR指令用亍从存储器中将一个32位的字数据传送到目的寄存器中。该指令通常用于从存储器中读取32位的字数据到通用寄存器,然后对数据进行处理。当程序计数器PC作为目的寄存器时,指令从存储器中读取的字数据被当作目的地址,从而可以实现程序流程的跳转。
3.20 STR:将32位字数据写入到指定的内存单元 STR指令的格式为:
STR指令用亍从源寄存器中将一个32位的字数据传送到存储器中。该指令在程序设计中比较常用,寻址方式灵活多样,使用方式可参考指令LDR。
1 2 3 STR R0,[R1],#8 ;将R0中的字数据写入以R1为地址的存储器中,并将新地址R1+8写入R1。 STR R0,[R1,#8] ;将R0中的字数据写入以R1+8为地址的存储器中。 str r1, [r0] ;将r1寄存器的值,传送到地址值为r0的(存储器)内存中
3.21 SWI:软中断指令 SWI指令格式如下:
MOV R0,#34 ;设置功能号为34
3.22 BIC清除位 1 BIC指令的格式为: BIC{条件}{S} 目的寄存器,操作数1,操作数2
BIC指令用于清除操作数1的某些位,并把结果放置到目的寄存器中。操作数1应是一个寄存器, 操作数2可以是一个寄存器、被移位的寄存器、或一个立即数。操作数2为32位的掩码,如果在 掩码中置了某一位1,则清除这一位。未设置的掩码位保持不变。
1 2 3 4 BIC R0,R0,#0X1F 0X1F=11111B BIC R4, R4, #0xFF000000 指令将E4高8位清除为0
3.23 EOR逻辑异或指令 1 EOR{<cond>}{S} <Rd>,<Rn>,<shifter_operand>
逻辑异或EOR(Exclusive OR)指令将寄存器中的值和的值执行按位“异或”操作,并将执行结果存储到目的寄存器中,同时根据指令的执行结果更新CPSR中相应的条件标志位。
3.24 CMN与负数对比 CMN 同于 CMP,但它允许你与负值进行比较,比如难于用其他方法实现的用于结束列表的 -1。这样与 -1 比较将使用:
3.25 MVN取反 将每一位操作数都取反,若为有符号的数据则进行补码保存
其中上图中的0x4用二进制数(00000100)表示, 然后对其取反得到(11111011),可见取反后为负数,因此针对负数求其补码则为储存在R0中的值,先将负数最高位转换为正数(01111011)取反,得到(10000100),加1得到其补码,最后结果为(10000101),即结果为-5;
3.26 LSL(Logical Shift Left)左移运算 用于将寄存器的值向左移位,末尾填充0。在ARM处理器中,每个寄存器都有32位,当LSL被使用时,指令将寄存器中的二进制数值向左移动指定的位数,并用0填充未使用的右侧位数。
3.27 STP STP是一条用于将General-Purpose Registers(通用寄存器)的值存储到内存地址的指令。STP是Store Pair的缩写,用于同时将两个寄存器的值存储到连续的内存地址中。
1 STP <Rt1>, <Rt2>, [<Xn|SP>, #<imm>]
Rt1和Rt2是要存储的寄存器,可以是X0-X30中的任何一个。
注意:结尾的!表示同时更新基础寄存器的值,即存储操作后,X18将指向下一个地址。如果不需要更新基础寄存器,可以省略!
实例解析 1 2 3 4 5 6 7 8 IMPORT |Image$RW_IRAM1$Base| IMPORT |Image$RW_IRAM1$Length| IMPORT |Load$RW_IRAM1$Base| IMPORT |Image$RW_IRAM1$ZI$Base| IMPORT |Image$RW_IRAM1$ZI$Length| Load$$region_name$$Base Load$$region_name$$Length Load$$region_name$$Limit
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 LDR R0, = |Load$RW_IRAM1$Base| LDR R1, = |Image$RW_IRAM1$Base| LDR R2, = |Image$RW_IRAM1$Length| CopyData SUB R2, R2, #4 LDR R3, [R0, R2] STR R3, [R1, R2] CMP R2, #0 BNE CopyData LDR R0, = |Image$RW_IRAM1$ZI$Base| LDR R1, = |Image$RW_IRAM1$ZI$Length| CleanBss SUB R1, R1, #4 MOV R3, #0 STR R3, [R0, R1] CMP R1, #0 BNE CleanBss IMPORT mymain BL mymain B . ENDP ALIGN END
Android系统源码基础 系统架构 应用层
用户可见的所有应用(系统自带或用户安装)
应用通过 API 与系统框架层交互
应用框架层
为开发者提供的核心 Java API
提供各种系统服务的访问接口,如:
模块
功能
ActivityManager管理应用生命周期和任务栈
WindowManager管理窗口显示与焦点
PackageManager管理应用安装、权限等
ContentProvider跨应用数据共享
NotificationManager通知控制
LocationManager定位服务
系统运行库层 Android Runtime(ART)
每个应用进程有独立的 ART 实例
负责:
执行 .dex 字节码(通过 JIT 或 AOT 编译)
管理内存、垃圾回收
C/C++ 原生库(Native Libraries)
库
功能
libc标准 C 库
libm数学库
OpenGL ES图形渲染
SQLite数据库存储
libmedia音视频编解码
硬件抽象层
定义标准接口,让上层服务无需关心具体硬件
OEM 厂商通过 HAL 实现对硬件的控制,比如:
模块
功能
camera.default.so摄像头驱动
audio.primary.so音频驱动
lights.default.so灯光控制
sensors.default.so传感器读取
Linux内核层
Android 运行在修改版的 Linux 内核上
提供:
线程管理
内存管理
电源管理
安全机制(SEAndroid)
驱动接口(用于与硬件直接通信)
源码目录结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 AOSP_ROOT/ ├── art/ → Android Runtime(ART) ├── bionic/ → C 标准库实现(libc、libm、libdl) ├── bootable/ → 启动引导(bootloader、recovery) ├── build/ → 构建系统脚本(makefile, Soong) ├── compatibility/ → CTS(兼容性测试套件) ├── dalvik/ → Dalvik 虚拟机(已被 ART 替代,保留部分兼容性) ├── development/ → 开发工具、调试工具 ├── device/ → 各品牌/型号的设备配置(BoardConfig.mk 等) ├── external/ → 第三方开源库(openssl、zlib、protobuf 等) ├── frameworks/ → Java 框架层源码(核心 API、系统服务) ├── hardware/ → 硬件抽象层(HAL)接口与实现 ├── kernel/ → Linux 内核源码(有时是 symbolic link) ├── libcore/ → Java 基础类库实现(java.lang, java.util等) ├── libnativehelper/ → JNI 帮助函数(native <-> Java 桥接) ├── packages/ → 系统应用(设置、桌面、输入法、浏览器等) ├── platform_testing/ → 平台测试框架 ├── prebuilts/ → 预编译的工具链(GCC、Clang、Java 等) ├── sdk/ → SDK 构建工具相关源码 ├── system/ → 核心系统服务(init、vold、core、server) ├── test/ → 测试相关内容 ├── tools/ → 构建工具集(adb、aapt 等) ├── vendor/ → 厂商特定代码(闭源驱动或 HAL 模块实现) └── out/ → 编译输出目录(构建后生成)
参考: https://wx.comake.online/doc/doc/SigmaStarDocs-SSD238X-Android-20240712/platform/Android/arch.html
Frida 使用 frida hook有两种模式,如下
将一个脚本注入到Android目标进程 使用usb进行hook frida -U -l myhook.js com.xxx.xxxx
-U 指定对USB设备操作
-l 指定加载一个Javascript脚本
最后指定一个进程名,如果想指定进程pid,用-p选项。正在运行的进程可以用frida-ps -U命令查看
使用host进行hook frida -l 0.0.0.0 5555相当于在手机启动一个监听,然后通过adb转发下端口,adb forward tcp:5555 tcp:5555就可以转发到本地,之后在 使用 frida -H 127.0.0.1:5555 -l test.js命令去加载脚本进行hook
**加 -f 包名**:启动 一个新的进程(就是指定的包名/应用),然后 在进程一启动起来(通常非常早期,甚至在 main 函数之前)就把你的脚本 注入 进去。spawn attach模式 (或者说spawn模式),resume() 继续进程。
不加 -f,直接指定一个正在运行的进程名/包名 :attach到已经在运行 的进程上,attach模式 。
Hook Java 一个hook的固定模版
1 2 3 4 5 6 7 8 9 10 11 12 Java .perform (function ( var <class_reference> = Java .use ("<package_name>.<class>" ); <class_reference>.<method_to_hook>.implementation = function (<args> ) { } })
Java.perform 是 Frida 中用于创建一个特殊上下文的函数,让你的脚本能够与 Android 应用程序中的 Java 代码进行交互。它就像是打开了一扇门,让你能够访问并操纵应用程序内部运行的 Java 代码。一旦进入这个上下文,你就可以执行诸如钩取方法或访问 Java 类等操作来控制或观察应用程序的行为。
Java.use方法用于加载一个Java类,相当于Java中的Class.forName()。比如要加载一个String类:var StringClass = Java.use("java.lang.String");var MyClass_InnerClass = Java.use("com.luoyesiqiu.MyClass$InnerClass");
带参数的构造函数 修改参数为byte[]类型的构造函数的实现
1 2 3 ClassName.$init.overload('[B' ).implementation=function(param){ }
注:ClassName是使用Java.use定义的类;param是可以在函数体中访问的参数
修改多参数的构造函数的实现
1 2 ClassName.$init.overload('[B' ,'int' ,'int' ).implementation=function(param1,param2,param3){ }
无参数构造函数 1 ClassName.$init.overload().implementation=function(){
调用原构造函数
1 ClassName.$init.overload().implementation=function(){
注意:当构造函数(函数)有多种重载形式,比如一个类中有两个形式的func:void func()和void func(int),要加上overload来对函数进行重载,否则可以省略overload
一般函数 修改函数名为func,参数为byte[]类型的函数的实现
1 ClassName.func.overload('[B' ).implementation=function(param){
无参数的函数 1 ClassName.func.overload().implementation=function(){
注: 在修改函数实现时,如果原函数有返回值,那么我们在实现时也要返回合适的值
1 ClassName.func.overload().implementation=function(){ //do something return this.func();}
调用函数 和Java一样,创建类实例就是调用构造函数,而在这里用$new表示一个构造函数。
1 2 var ClassName=Java.use("com.luoye.test.ClassName" );var instance = ClassName.$new ();
实例化以后调用其他函数
1 2 3 var ClassName=Java.use("com.luoye.test.ClassName" );var instance = ClassName.$new ();instance.func();
字段操作 字段赋值和读取要在字段名后加.value,假设有这样的一个类:
1 2 3 4 5 package com.luoyesiqiu.app;public class Person { private String name; private int age; }
写个脚本操作Person类的name字段和age字段:
1 2 3 4 5 6 7 8 var person_class = Java .use ("com.luoyesiqiu.app.Person" );var person_class_instance = person_class.$new();person_class_instance.name .value = "luoyesiqiu" ; person_class_instance.age .value = 18 ; console .log ("name = " ,person_class_instance.name .value , "," ,"age = " ,person_class_instance.age .value );
输出:
1 name = luoyesiqiu , age = 18
类型转换 用Java.cast方法来对一个对象进行类型转换,如将variable转换成java.lang.String:
1 2 var StringClass =Java .use ("java.lang.String" );var NewTypeClass =Java .cast (variable,StringClass );
Java.available字段 这个字段标记Java虚拟机(例如: Dalvik 或者 ART)是否已加载, 操作Java任何东西之前,要确认这个值是否为true
Java.perform(fn)在Javascript代码成功被附加到目标进程时调用,我们核心的代码要在里面写。格式:
1 Java.perform(function(){
参考:https://www.daowuya.love/frida%E7%94%A8%E6%B3%95%E4%B9%8Bhook-java%E5%B1%82%E4%BB%A3%E7%A0%81/
来看一个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 package a.b.k0801; import androidx.appcompat.app.AppCompatActivity; import android.os.Bundle;import android.view.LayoutInflater;import android.view.View;import android.widget.Button;import android.widget.EditText;import android.widget.TextView; import java.security.MessageDigest;import java.security.NoSuchAlgorithmException; import a.b.k0801.databinding.ActivityMainBinding; public class MainActivity extends AppCompatActivity { static {System.loadLibrary("k0801" ); } private ActivityMainBinding binding; @Override protected void onCreate (Bundle savedInstanceState) {super .onCreate(savedInstanceState); binding = ActivityMainBinding.inflate(getLayoutInflater()); setContentView(binding.getRoot()); EditText et_userName = binding.etUserName;EditText et_key = binding.etKey;TextView tv_result = binding.tvResult;Button btn_reg = binding.btnOk;btn_reg.setOnClickListener(new View .OnClickListener() { @Override public void onClick (View view) {if (checkSN(et_userName.getText().toString().trim(), et_key.getText().toString().trim())){tv_result.setText("注册成功!" ); }else { tv_result.setText("注册失败!" ); } } }); } private boolean checkSN (String userName, String sn) {try {if ((userName == null ) || (userName.length() == 0 ))return false ;if ((sn == null ) || (sn.length() != 16 ))return false ;MessageDigest digest = MessageDigest.getInstance("MD5" );digest.reset(); digest.update(userName.getBytes()); byte [] bytes = digest.digest(); String hexstr = bytes.toString(); StringBuilder sb = new StringBuilder ();for (int i = 0 ; i < hexstr.length(); i += 2 ) {sb.append(hexstr.charAt(i)); } String userSN = sb.toString(); if (!userSN.equalsIgnoreCase(sn)) return false ;} catch (NoSuchAlgorithmException e) { e.printStackTrace(); return false ;} return true ;} public native String stringFromJNI () ;}
hook脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 function hook_java_main ( Java .perform (() => { var cls_MainActivity = Java .use ("a.b.k0801.MainActivity" ); var fun_checkSN = cls_MainActivity.checkSN .overload ('java.lang.String' , 'java.lang.String' ); fun_checkSN.implementation = function (p0, p1 ){ console .log ("checkSN in:" , p0, p1); p0 = "cccc" ; p1 = "dddd" ; var ret = this .checkSN (p0, p1); ret = true ; console .log ("checkSN out:" , ret); return ret; }; console .log ("hook_java_main run over" ); }); } setTimeout (hook_java_main, 0 );
Hook Native Hook Native层中调用的函数并且读取传入的参数 先来看看模版
1 2 3 4 5 6 7 8 9 10 Interceptor .attach (targetAddress, { onEnter : function (args ) { console .log ('Entering ' + functionName); }, onLeave : function (retval ) { console .log ('Leaving ' + functionName); } });
Interceptor.attach:将回调函数附加到指定的函数地址。targetAddress 应该是我们想要挂钩的本地函数的地址。onEnter:当挂钩的函数被调用时,调用此回调。它提供对函数参数 (args) 的访问。onLeave:当挂钩的函数即将退出时,调用此回调。它提供对返回值 (retval) 的访问。
需要获取targetAddress我们可以方便的使用如下API:
Module.enumerateExports()
Module.getExportByName()
Module.findExportByName()
Module.getBaseAddress()
Module.enumerateImports()
参考: https://blog.csdn.net/qq_24481913/article/details/136546413
对于没有导出的函数如何进行hook呢,就要利用ida找出该函数在内存中的便宜加上基址
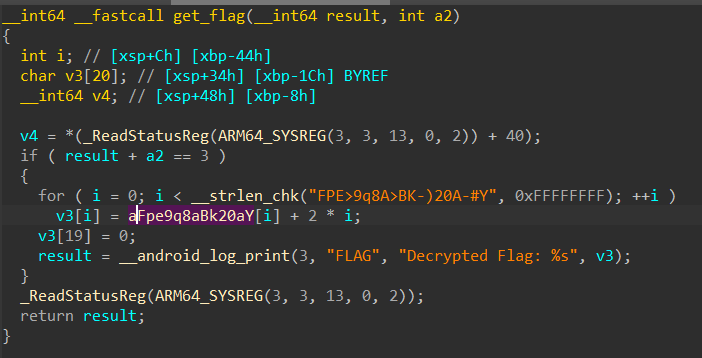
1 2 3 4 5 6 7 8 9 10 11 12 var base = Module .findBaseAddress ("libtarget.so" );var target = base.add (0x1234 );Interceptor .attach (target, { onEnter : function (args ) { console .log ("hooked non-exported function" ); }, onLeave : function (retval ) { console .log ("return value:" , retval); } });
Hook修改native层程序返回值 hook的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 function hook ( var check_flag = Module .enumerateExports ("liba0x9.so" )[0 ]["address" ]; console .log ("Func address = " ,check_flag); Interceptor .attach (check_flag,{ onEnter :function (args ){ },onLeave :function (retval ){ console .log ("Origin retval : " ,retval); retval.replace (1337 ); } }) } function main ( Java .perform (function ( hook (); }) } setImmediate (hook);
调用native层中未被调用的方法 1 2 3 var native_adr = new NativePointer (<address_of_the_native_function>);const native_function = new NativeFunction (native_adr, '<return type>' , ['argument_data_type' ]);native_function (<arguments >);
1 var native_adr = new NativePointer (<address_of_the_native_function>);
要在 Frida 中调用一个本地函数,我们需要一个 NativePointer 对象。我们应该将要调用的本地函数的地址传递给 NativePointer 构造函数。接下来,我们将创建 NativeFunction 对象,它表示我们想要调用的实际本地函数。它在本地函数周围创建一个 JavaScript 包装器,允许我们从 Frida 调用该本地函数。
1 const native_function = new NativeFunction (native_adr, '<return type>' , ['argument_data_type' ]);
第一个参数应该是 NativePointer 对象,第二个参数是本地函数的返回类型,第三个参数是要传递给本地函数的参数的数据类型列表。现在我们可以像在 Java 空间中那样调用该方法了。
1 native_function (<arguments >);
看看例子
发现就是在主函数中加载了stringFromJNI,没有关于flag的信息,但是有未被调用的flag函数,我们直接使用hook调用它输出log
hook代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 function hook ( var a = Module .findBaseAddress ("libfrida0xa.so" ); var b = Module .enumerateExports ("libfrida0xa.so" ); var get_flagaddress = null ; var mvaddress = null ; for (var i = 0 ; b[i]!= null ; i ++ ){ if (b[i]["name" ] == "_Z8get_flagii" ){ console .log ("function get_flag : " ,b[i]["address" ]); console .log ((b[i]["address" ] - a).toString (16 )); get_flagaddress = b[i]["address" ]; } } console .log (ptr.toString (16 )); var get_flag_ptr = new NativePointer (get_flagaddress); const get_flag = new NativeFunction (get_flag_ptr,'char' ,['int' ,'int' ]); var flag = get_flag (1 ,2 ); console .log (flag) } function main ( Java .perform (function ( hook (); }) } setImmediate (main)
主动调用native中的函数 1、new NativeFunction(要调用的函数地址,函数返回值,[参数]);
如下演示了一个写入字符到文件中的示例
1 2 3 4 5 6 7 8 9 10 11 12 var fopen_addr = Module .findExportByName ("libc.so" , "fopen" );var fopen = new NativeFunction (fopen_addr, "pointer" , ["pointer" , "pointer" ]);var fputs_addr = Module .findExportByName ("libc.so" , "fputs" );var fputs = new NativeFunction (fputs_addr, "int" , ["pointer" , "pointer" ]);var fclose_addr = Module .findExportByName ("libc.so" , "fclose" );var fclose = new NativeFunction (fclose_addr, "int" , ["pointer" ]);var filename = Memory .allocUtf8String ("/sdcard/a.txt" );var mod = Memory .allocUtf8String ("a" );var neirong = Memory .allocUtf8String ("aaaaaaaa\r\nbbbb\r\b" );var fp = fopen (filename, mod);fputs (neirong, fp);fclose (fp);
打印堆栈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 function printJavaStack ( Java .perform (function ( var Exception = Java .use ("java.lang.Exception" ); var instance = Exception .$new("print_stack" ); var stack = instance.getStackTrace (); console .log (stack); instance.$dispose(); }); } function printNativeStack (context, str_tag ){ console .log ("\r\n=============================" + str_tag + " Stack in =======================\r\n" ); console .log (Thread .backtrace (context, Backtracer .ACCURATE ).map (DebugSymbol .fromAddress ).join ('\n' )); console .log ("\r\n=============================" + str_tag + " Stack out =======================\r\n" ); } function hook_java_main ( Java .perform (function ( var cls_act = Java .use ("a.b.k0805.MainActivity" ); var fun_z = cls_act.z .overload (); fun_z.implementation = function ( console .log ("hook java z() in" ); var ret = this .z (); printJavaStack (); console .log ("hook java z() out" ); return ret; } console .log ("hook_java_main out" ); }); } function hook_native_main ( var base_so = Module .findBaseAddress ("libk0805.so" ); if (base_so){ console .log ("base_so:" , base_so); var real_addr_z = base_so.add (0x1DFD0 ); Interceptor .attach (real_addr_z, { onEnter ( console .log ("hook onEnter z()" ); printNativeStack (this .context , "current native z()" ); }, onLeave (retval ) { console .log ("hook onLeave z()" ); } }); } console .log ("hook_native_main out" ); } setTimeout (hook_native_main, 2000 );hook_java_main ();
使用frida 追踪jni函数动静态注册 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 function hook_one (funName, funAddr ) { Interceptor .attach (funAddr, { onEnter : function (args ) { console .log (funName, " call in" ); }, onLeave : function (retVal ) { } }); } function hook_explorts ( var modules = Process .enumerateModules (); for (var j = 0 ; j < modules.length ; j++) { var oneModule = modules[j]; if (oneModule.name .indexOf ("0808" ) == -1 ) continue ; console .log ("oneModule:" , oneModule.name ); var funList = oneModule.enumerateExports (); for (var k = 0 ; k < funList.length ; k++) { var oneFun = funList[k]; if (oneFun.name .indexOf ("Java_" ) == -1 && oneFun.name .indexOf ("getAAA" ) == -1 ) continue ; console .log ("oneFun:" , oneFun.name ); hook_one (oneFun.name , oneFun.address ); } } } function hook_java_main ( Java .perform (function ( console .log ("hook_java_main in" ); hook_explorts (); console .log ("hook_java_main out" ); }); } setTimeout (hook_java_main, 2000 );